An open-source framework that deploys JAMstack + Serverless applications
Create. Develop. Build. Deploy.
Create. Develop. Build. Deploy.
Jolt allows a user to create a project, develop locally, build your static site, and deploy to AWS within minutes.
Case Study
0. Introduction
Jolt is a lightweight, open-source framework that makes it easy to develop, deploy, and maintain JAMstack applications with serverless functions. It abstracts away the complexity of provisioning and managing infrastructure, allowing the developer to focus on the business logic of their application. Jolt is targeted towards developers who are interested in the easy development, high scalability and low latency that the JAMstack model provides, but who also need a secure, scalable environment to perform computation that can’t be done on the client.
To get started, we’ll introduce the functionality that Jolt provides.
0.1 Jolt Quickstart Guide
To get started with Jolt, run: npm install -g jolt-framework
Note: Jolt assumes that the user has configured their AWS credentials locally through the AWS CLI with the command aws configure.
Here is a list of Jolt commands: (All commands should be run from the root of the application)
Command
Description
jolt init
Initialize an application for use with Jolt: Prompts the user to answer a series of questions about the application. Answers are stored in a local configuration file that Jolt references while running other commands.
jolt dev
Spins up the user’s front end development server + Lambda development server in order to allow the full application to be run locally.
jolt functions
Spins up the Lambda development server by itself.
jolt deploy
Deploys the application on AWS.
jolt update
Builds and deploys the latest version of a previously deployed application. The underlying infrastructure is reused wherever possible.
jolt rollback
Prompts the user to select from a list of versions associated with the current application. Once a version is selected, the front end and Lambdas are reverted to that version.
jolt destroy
Removes an application and all of its associated AWS infrastructure.
jolt lambda [function_name]
Creates a Lambda template in the functions folder with the specified function_name.
Jolt has been tested for use with React and Gatsby applications but by specifying other build commands during initialization, other frameworks can be used as well.
For more information on getting started with Jolt, please visit the documentation on our GitHub page.
The following chapters will go into detail about the JAMstack + Serverless Architecture, how we built Jolt and the challenges we overcame along the way.
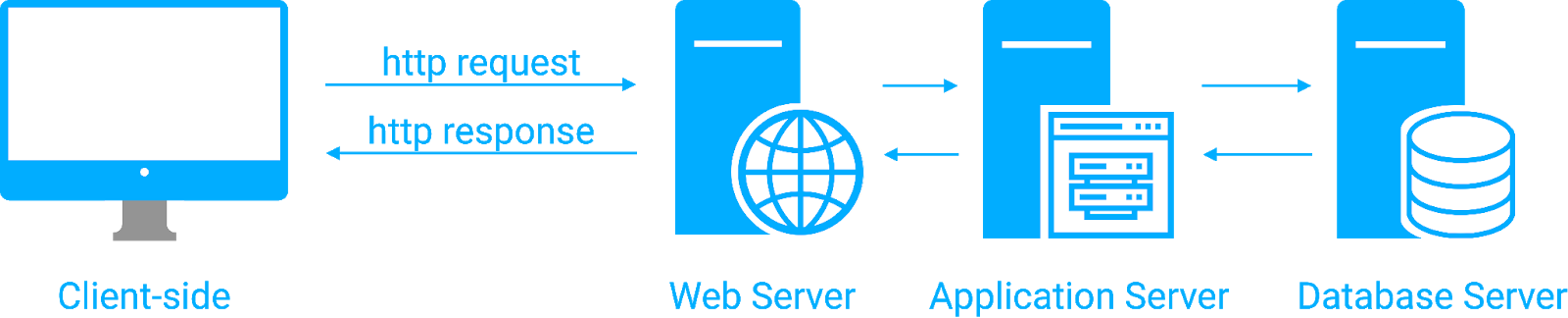
1. Traditional Web Application Architecture
The term “web application architecture” refers to all of the software and hardware components that make up a web application as well as the interactions between those components1. Every web application architecture has two sides, the client and the server side.
1.1 How Web App Architectures Work
Communication between the client and server is performed using http requests and responses. For developers, much of defining a web app architecture is about deciding what activity happens on the client-side, and what activity occurs on the server-side.
A web browser (the client) makes an http request to a web server which, in this case, returns static assets such as html and images for the browser to render.
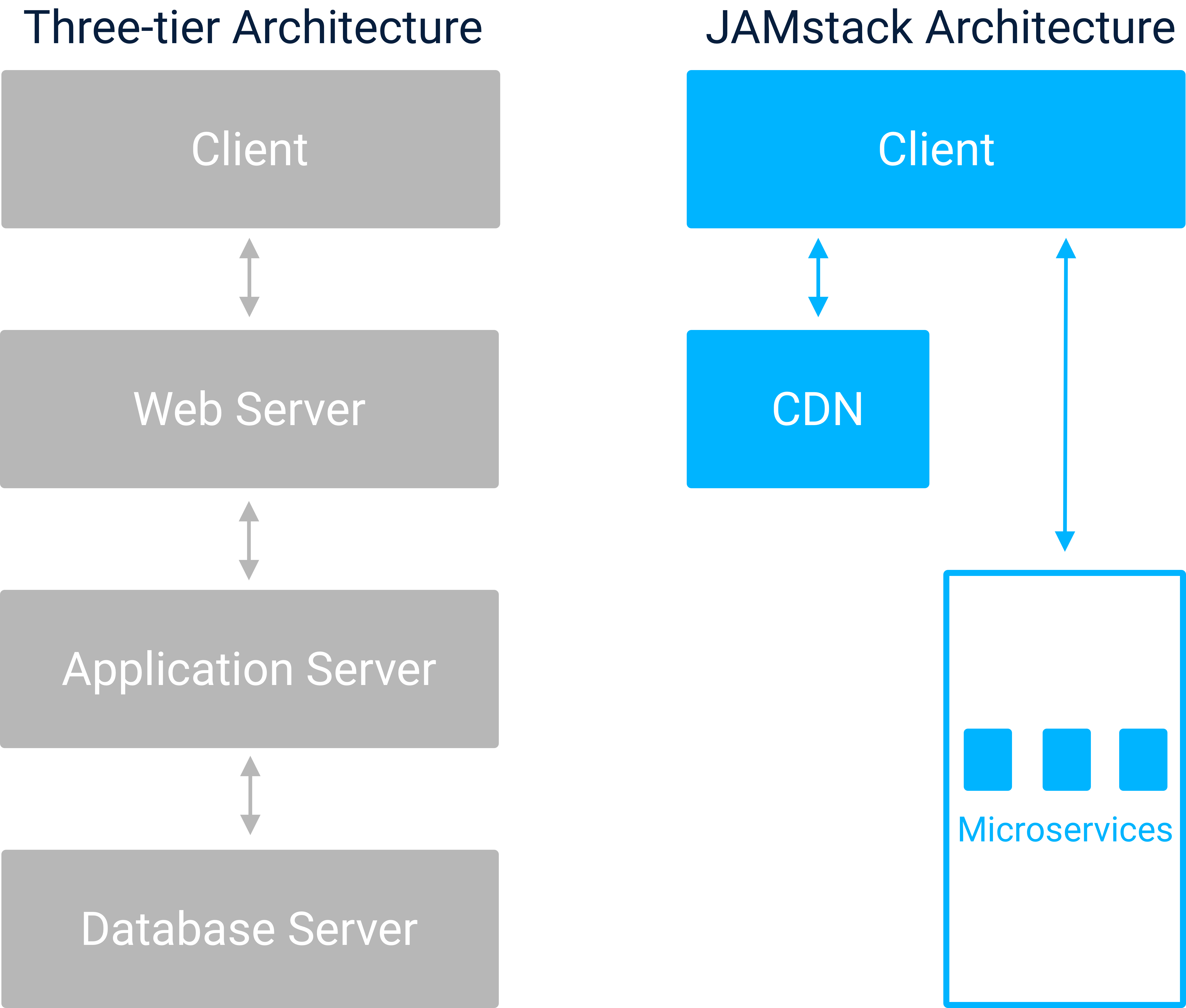
1.2. The Three-Tier Architecture
A three-tier architecture consists of three “layers” of infrastructure: a web server, an application server, and a database.
The web server is the outer layer in a three-tier architecture. Web servers mostly handle serving of static assets and routing of requests to other layers of the application infrastructure when needed.
Application servers are built to process requests that require some computation and thus can’t be handled by a web server which is optimized for delivering static content. The application server can handle dynamic processes like payment processing, inventory management, or any other business logic the application needs.
With the application server providing dynamic content and the web server serving up static content, we need somewhere to actually store the data associated with this content. This brings us to the final layer in a three-tier architecture, the database.
The database stores persistent data so that it can be retrieved by the application or web servers on demand and sent to clients.
The three-tier architecture
With this completed three-tier architecture, a developer has a back end that can store data, perform computation and serve up static and dynamic content to users.
1.3 Expanding Beyond the Three-Tier Architecture
As applications grow in scope and popularity, additional pieces of infrastructure may be needed. For instance:
Additional web, application or database servers
Load balancers to distribute traffic across the additional servers
Caching layers
Expanding the three-tier architecture with a load balancer, cache, and additional web, application, and database servers.
Implementing more complex architectures allows developers to have more control over their application. However, the additional complexity results in:
Increased difficulty of developing and maintaining the application
Increased time and financial costs associated with provisioning and managing the additional infrastructure
New architectures have emerged that help to abstract away the complexity and cost of building and maintaining web applications. One such architecture is the JAMstack architecture.
2. How the JAMstack Architecture Works
"A modern web development architecture based on client-side JavaScript, reusable APIs, and prebuilt Markup."
JAMstack as a term was popularized by Chris Bach and Matthias Biilmann of Netlify. The above quote by Biilmann nicely summarizes the 3 pillars of the JAMstack architecture: JavaScript, APIs and Markup. Let’s break each of those down.
Markup
In a three-tier architecture, servers usually perform just in time rendering. This means that content is generated when it is requested by a client. By generating content when it is requested, sites can provide a dynamic experience with personalized or context dependent content. However, the tradeoff with this approach is that the process of generating content for each request costs extra time and memory.
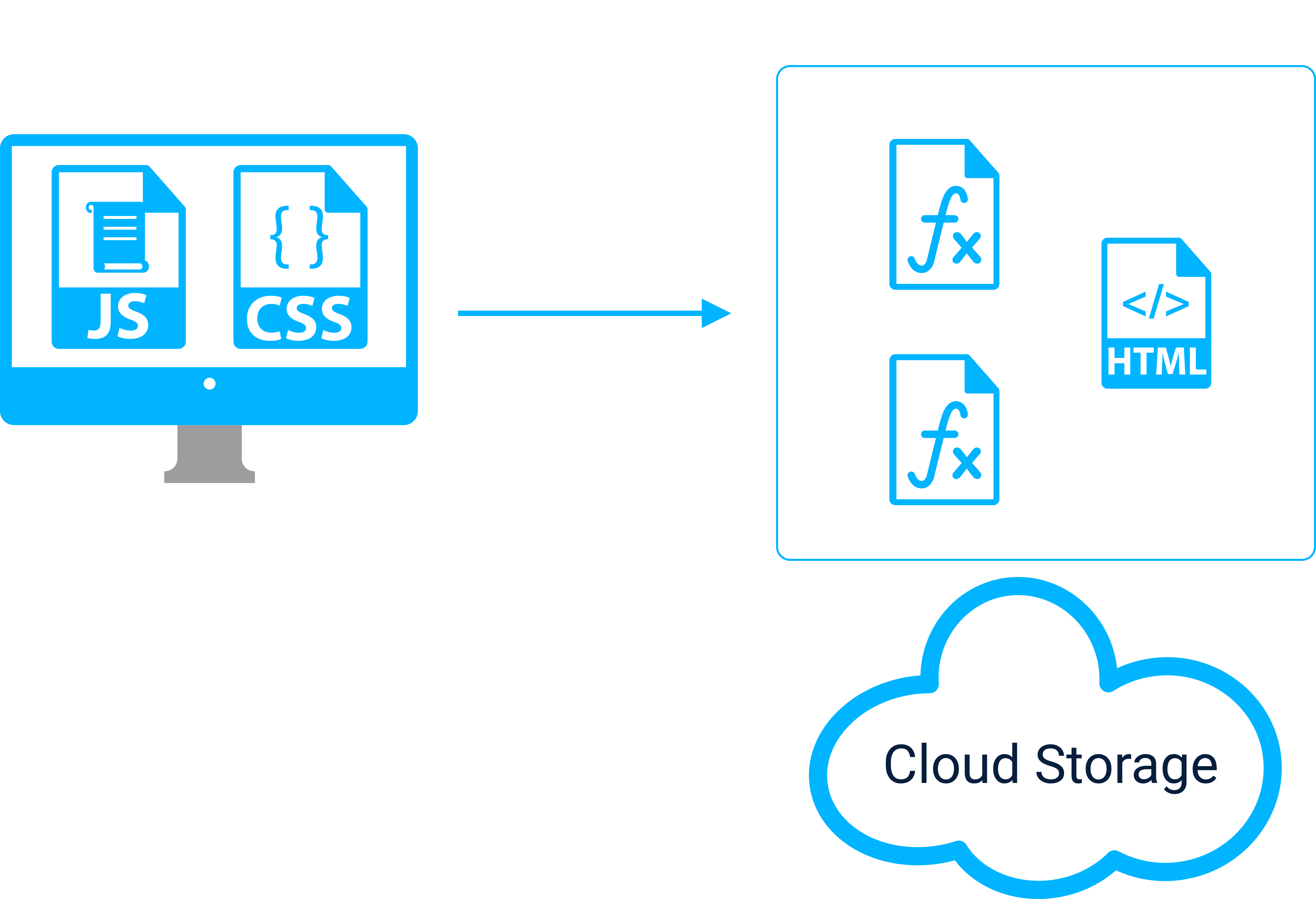
Instead of paying this cost with each request, the JAMstack approach relies on ahead of time rendering. This process involves pre-building pages which is typically done using a static site generator such as Hugo or Gatsby.
The typical flow of a static site generation process wherein the website content is assembled into static HTML pages, uploaded to a CDN, and then accessed by the user.
This process bundles the application code into a collection of static HTML files. While this can take a while, after it’s been done once, the resulting collection of static files is ready to be served up and rendered immediately on the client. Phil Hawksworth, Director of Developer Experience at Netlify refers to this as “Doing the work now so your servers don’t have to3”.
Contrast this with the three-tier architecture where pages are re-built for every request, and it becomes clear that an approach of pre-rendering content will lead to much faster page load times in the long run.
After the content has been pre-built, it is cached on globally distributed CDN (Content Delivery Network) servers. Then, when a page is requested, the CDN server nearest to the client can send the requested page back with minimal latency. The use of a CDN for serving static content can eliminate the need for running a web server.
APIs
The next piece of the JAMstack centers around the idea that most of the work traditionally done by the application server and database server layers can be performed by 3rd party services. The job of handling things like search, authentication or payment processing can be outsourced to domain experts who provide reliable, fully featured solutions that can be easily plugged into an application without the cost and complexity of building your own.
Popular 3rd Party APIs
By using 3rd party APIs, complex computation and even data persistence can be handled without the need for database and application servers.
JavaScript
Client-side JavaScript is used to retrieve and render the kind of dynamic content that would traditionally have been handled by a backend language like Node, Python, Ruby, etc. The browser uses JavaScript to make client-side calls to 3rd party APIs and then to perform DOM manipulation to update the view on the client side as needed.
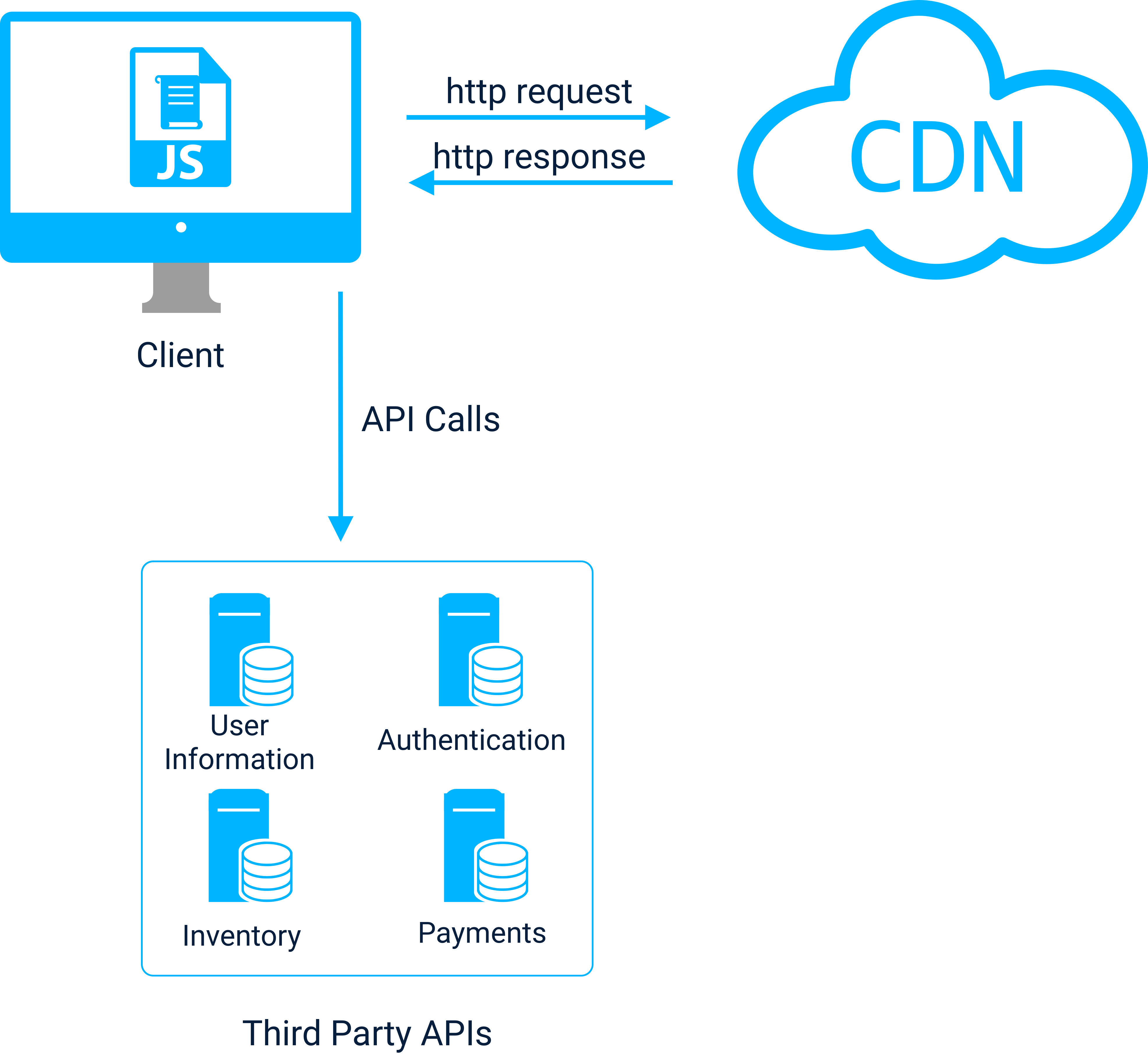
2.1 The JAMstack Architecture
The JAMstack architecture: JavaScript in the browser, 3rd party API calls, Markup from a CDN
An application built with a JAMstack architecture uses client-side JavaScript to make API calls and perform DOM manipulations. 3rd APIs handle processes like search, authentication, or data persistence. Finally, Markup is cached and served from a CDN to provide fast, scalable content to clients.
2.2 Contrasting JAMstack with the Three-tier Architecture
Contrasting the Three-tier architecture with the JAMstack architecture
.
By viewing the JAMstack architecture alongside the three-tier architecture, it’s easy to see how they differ. With JAMstack, the serving of static content typically handled by the web server is now handled by a CDN. The business logic and persistent storage that would traditionally have been handled by a database and application server are now all abstracted away into 3rd party APIs that can perform any computation or data persistence that the application needs.
2.3 Advantages of the JAMstack
Beyond the simpler developer experience of not needing to build and manage servers, using the JAMstack has several major benefits4:
Performance
By pre-building pages and using a CDN to cache and serve all static content, response times are faster because the page rendering that would have occurred at response time has already been completed by a static site generator.
Security
With no backend servers to manage, the surface area of the application is much smaller. With fewer pieces of infrastructure, the number of potential security risks is greatly reduced.
Scalability
A JAMstack architecture eliminates the need for manually adding and removing servers in order to scale your application, as is often required with a three-tier architecture. Because application traffic is handled by CDN servers which are managed by a cloud provider, scalability comes built in, as the cloud provider takes care of fluctuations in traffic to your application and only bills you for what you use.
While there are plenty of advantages to the JAMstack approach, it’s important to be aware that it’s not a fit for every use case and tradeoffs are made when using it.
2.4 Tradeoffs of the JAMstack
There are two main tradeoffs that come with a JAMstack Architecture: long build times and the lack of custom compute.
Long Build Times
Depending on the size of the application, generating static pages with a static site generator such as Hugo or Gatsby can take anywhere from minutes to hours5.
For sites that receive constant updates, like a news site, the need to frequently rebuild static pages would be a burden that could make the JAMstack approach infeasible.
Lack of Custom Compute
There are some cases where computation needs to be done that can’t be executed in the browser and for which no 3rd party API provides a complete solution.
In these cases, a backend server could be spun up, however doing so reintroduces some of the architectural complexity that the JAMstack architecture tries to abstract away.
A way of performing secure computation is needed that doesn’t require spinning up and managing a server. One way to deal with this is by implementing a serverless architecture.
3. The Serverless Architecture
The term “serverless” architecture refers to a cloud computing model where the servers are entirely managed by a 3rd party. In essence, the developer writes the business logic of their application and a cloud provider takes care of the provisioning and management of servers. Most often the term is used to refer to serverless functions, or Function as a Service (FaaS).
3.1 Serverless Functions
Amazon Web Services describes serverless functions as "A compute service that lets you run code without provisioning or managing servers... or managing runtimes."6
Serverless functions allow developers to work at a level of abstraction where they only need to select a runtime and write the code needed to achieve the desired functionality. After that, the code is given to a FaaS provider who will handle starting the functions (and stopping them when not in use), scaling them as traffic increases and decreases, and managing all of the underlying infrastructure.
As more requests are made, serverless functions easily scale up or down to meet demand.
There are several technical limitations to be aware of when evaluating whether or not serverless functions are good fit for a given use case.
Execution Time Limits
Serverless functions are generally designed for shorter computation tasks. Maximum execution time limits range from about 5 to 15 minutes.
Cold Starts
When a function has not been used for at least 5-10 minutes, a delay called a cold start occurs because the function needs to be spun up again. Cold starts result in additional latency and must be factored into application design.
4 The JAMstack + Serverless Architecture
Serverless functions provide a solution for the lack of custom compute inherent in the JAMstack architecture and the combination of JAMstack and serverless is becoming increasingly popular. Ryan Coleman, VP of Engineering at Stackery, a company focused on the design and deployment of serverless web applications said: “Serverless + JAMstack is where web app architectures are going7.”
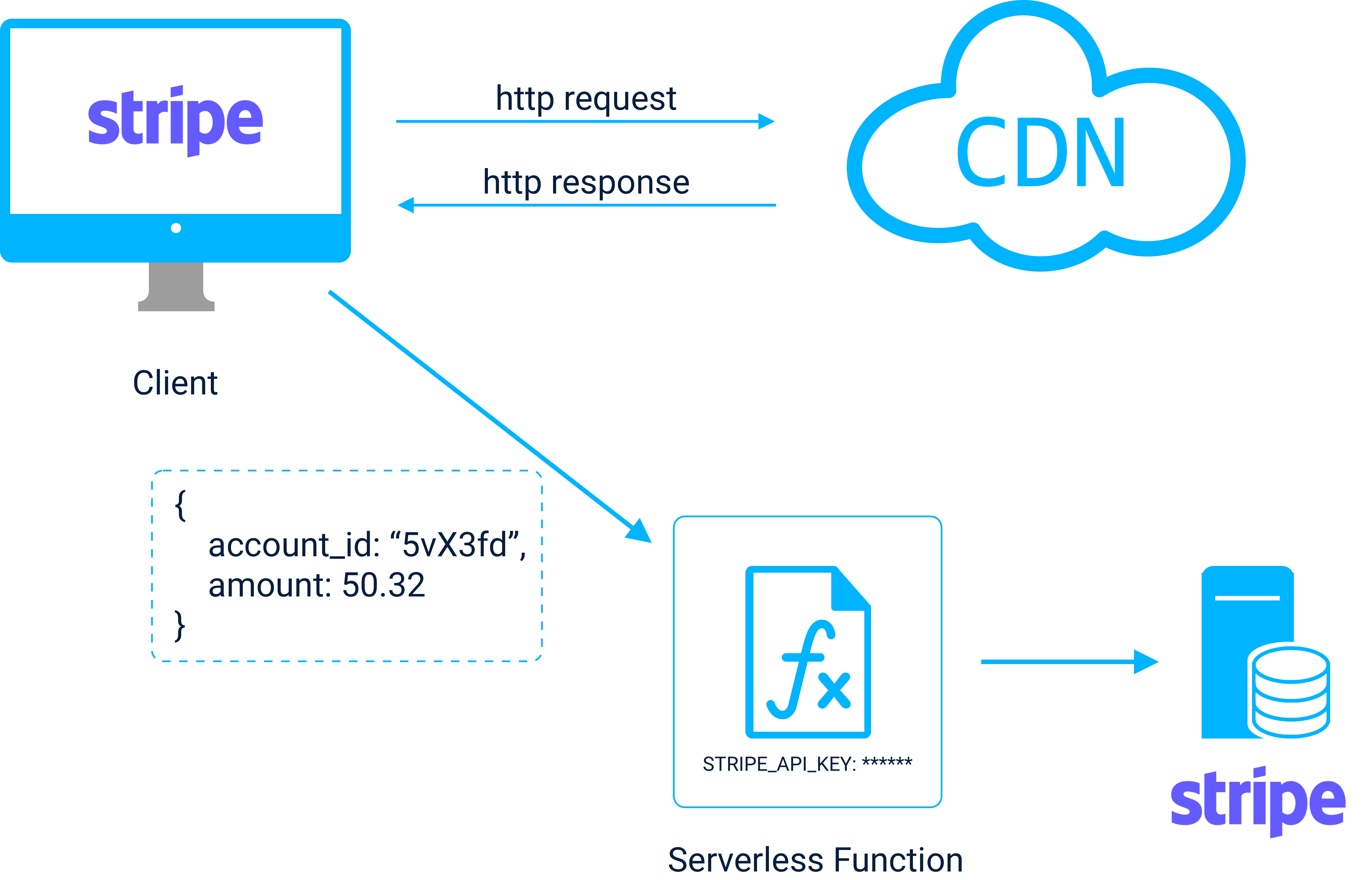
To illustrate when how the JAMstack + serverless combination can be useful, we'll take a look at a common use case: Dealing with secret API keys when interacting with a 3rd party API like Stripe8.
When a user visits an e-commerce site that uses Stripe to process payments, the Stripe front-end client can be used to collect details related to billing. However, in order to checkout, the Stripe backend client is used, which requires an API key. Since this is a secret key that can’t be sent directly to the client for security reasons, a secure computing environment is needed to store the key and interface with Stripe’s API.
Serverless functions provide a way of securely interacting with the Stripe backend API.
The Stripe client API is used to collect payment details which are sent to a serverless function that interfaces with Stripe directly using a secret API key.
In a JAMstack + serverless application, the payment information can be sent from the client to a serverless function that holds the Stripe API key. The function can then securely contact Stripe on the client’s behalf, await a response and then send the confirmation back to the client. This approach allows for secure processing of payments without the need to provision and manage complicated back end servers.
By adding serverless functions to the JAMstack architecture, applications regain the ability to perform custom computation that was lost by removing backend servers from the architecture.
4.1 Building JAMstack + Serverless From Scratch
Now that we’ve introduced the JAMstack + Serverless architecture and seen why a JAMstack application might need serverless functions, we’ll take a look at the 4 core pieces of infrastructure needed to deploy such an application:
Content Delivery Network
Static Asset Store (Origin)
API Gateway
Serverless Functions
Content Delivery Network
A content delivery network, or CDN, is a globally distributed network of servers designed to cache web content and serve it to clients with minimal latency. Because of their global scope, client requests can be sent to a CDN server nearest to them, instead of needing to be routed to a central server farther away. This results in much faster response times. In addition, CDNs are highly scalable because increased traffic to an application is automatically spread out to other CDN servers in the proximity of the user.
Static Asset Store
The static assets that make up a JAMstack application aren’t actually hosted on CDN servers. Instead, the files need to be stored in a location that acts as a source of truth. This location is known as the “origin”. Files on the origin are retrieved by the CDN and cached before they are served to clients.
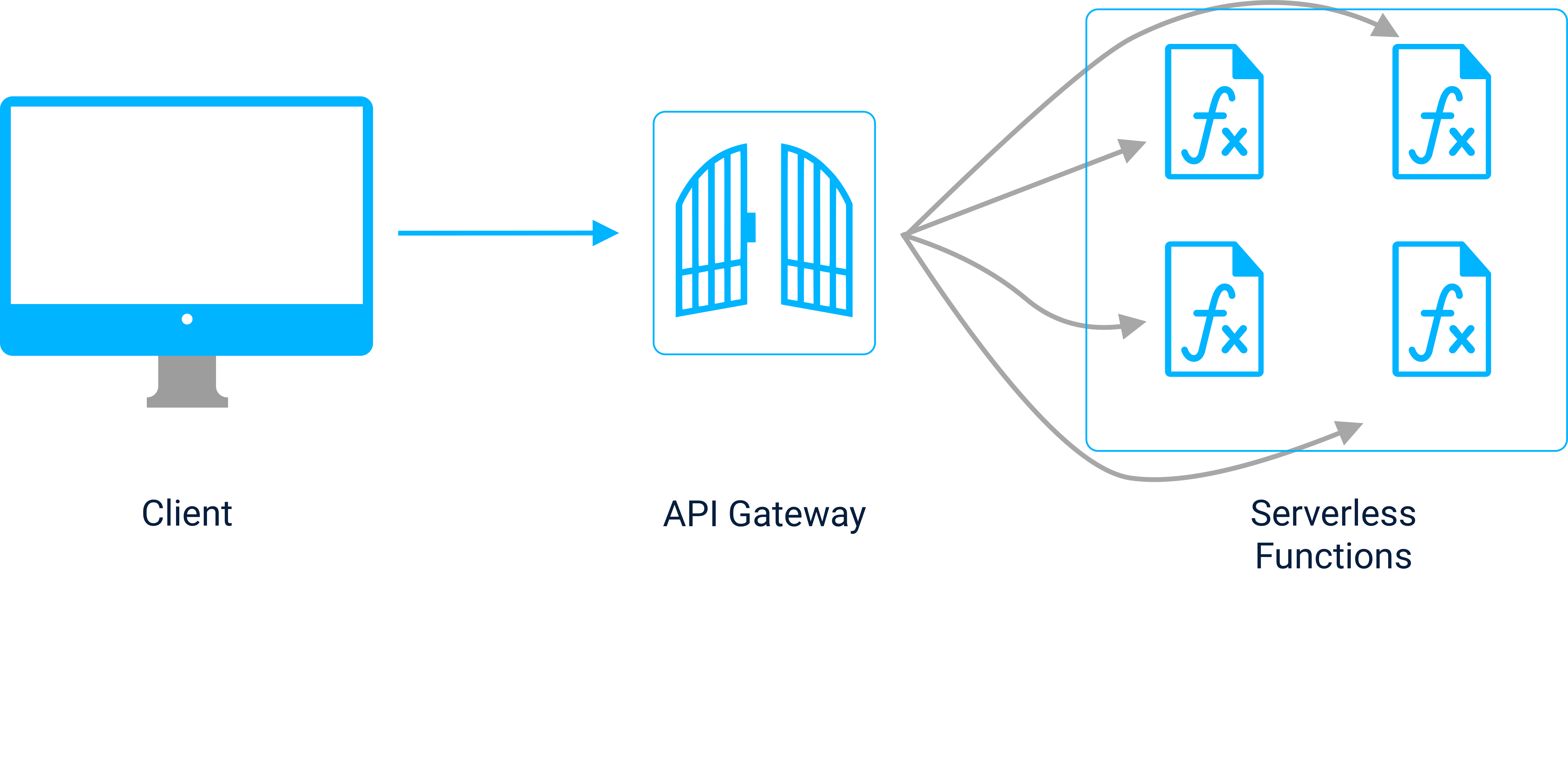
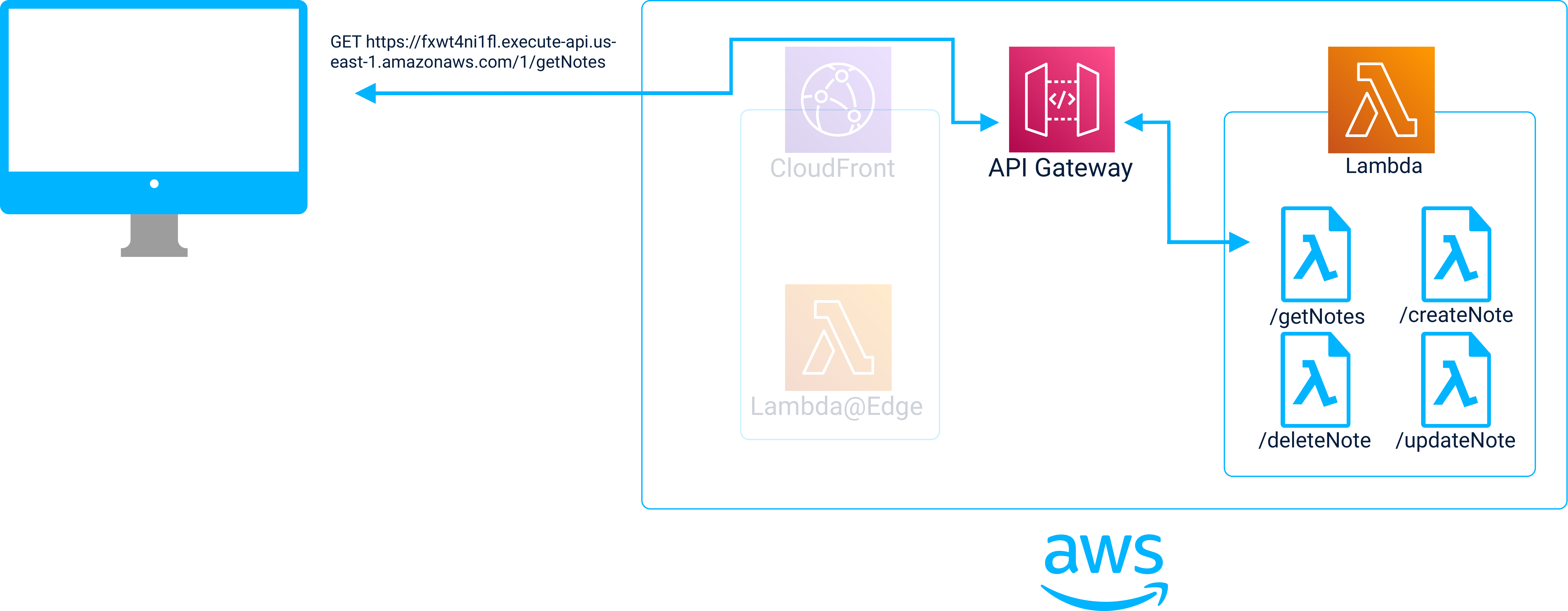
API Gateway
Serverless functions aren’t accessible by the client out of the box. In order to allow requests to be sent to serverless functions, an API gateway is needed. To connect a serverless function to the gateway, the route and method that will be used to reach the function must be specified. Then, the function is integrated into the Gateway so that requests sent to the gateway at that route/method combination can be proxied to the function. When a request is received by a function, it gets invoked and the resulting output is returned in a response to the client via the gateway.
Manually Deploying a JAMstack + Serverless Application
At a minimum, in order to get a JAMstack application with serverless functions running manually, the 4 pieces of infrastructure discussed above need to be provisioned on a cloud provider. When done using Amazon Web Services through their browser console, more than 50 individual steps are required. Even if the developer knows what to do, this is a tedious and time consuming process.
There are a number of solutions that streamline this process for developers, avoiding the hassle of provisioning and managing infrastructure so they can instead focus on building the business logic of the application.
4.2 JAMstack + Serverless Solutions
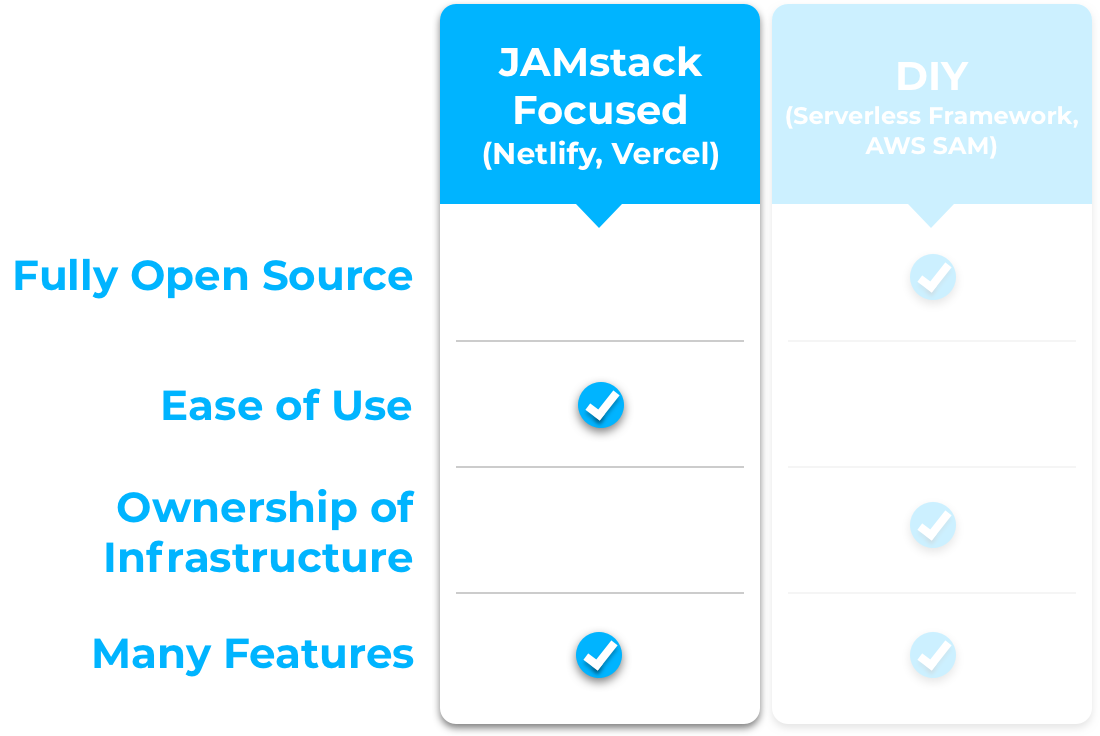
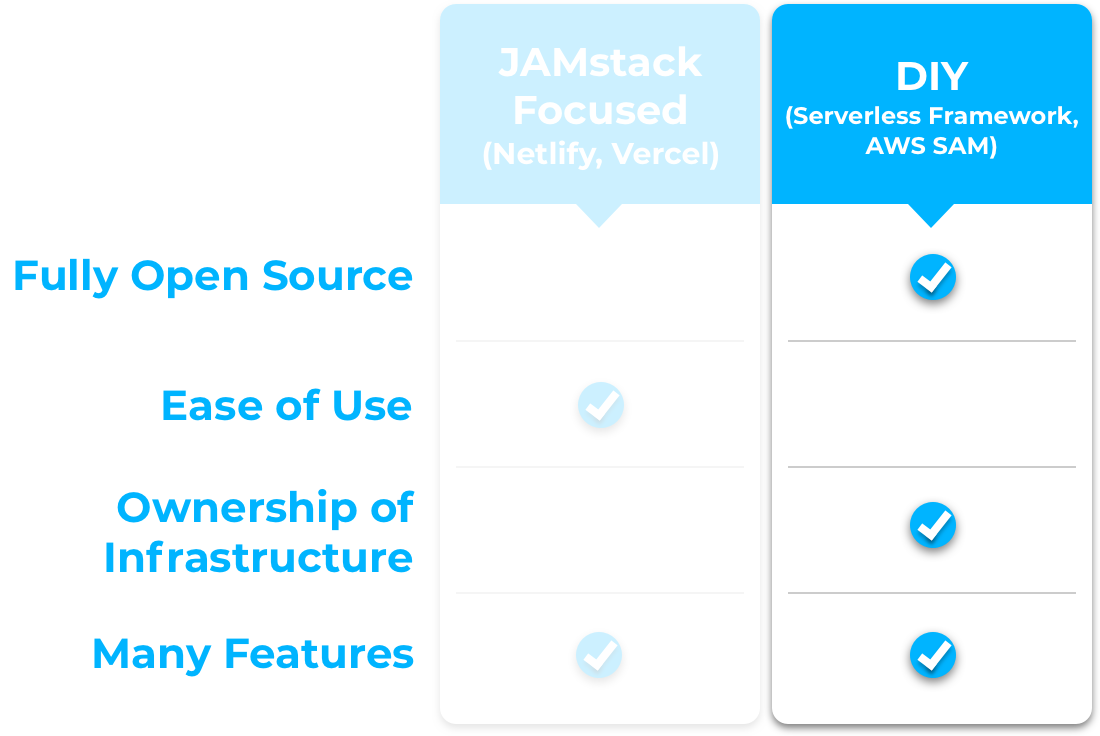
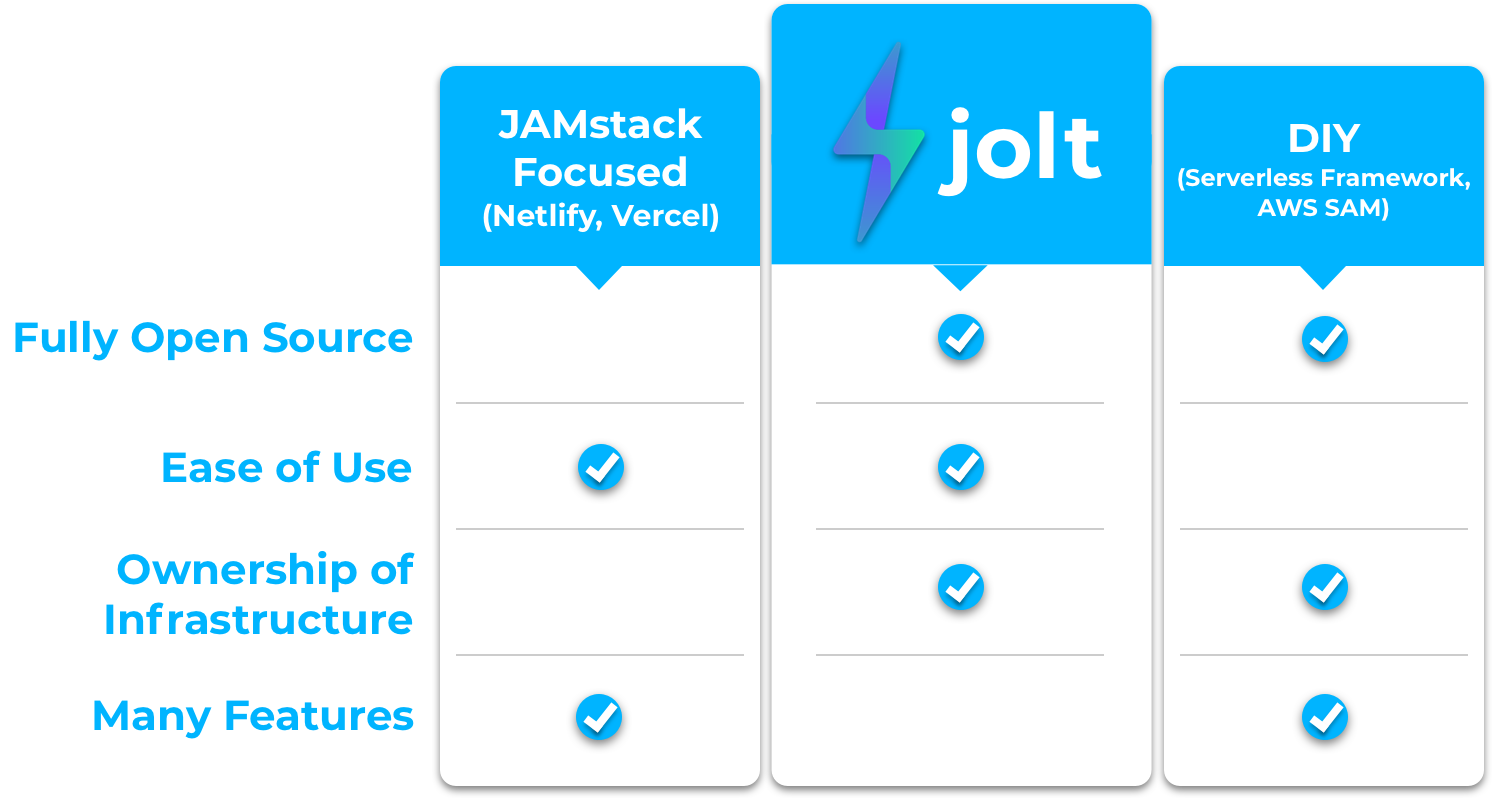
These solutions tend to fall into one of two major categories: JAMstack focused or DIY9.
JAMstack Focused Solutions
Netlify and Vercel are two companies we explored that provide a JAMstack focused development experience. They streamline development and take care of the deployment and management of JAMstack applications with serverless functions. With these solutions, a developer writes code and provides some configuration details and they take care of the rest of the work. They also come with many additional useful features like a local development server and continuous deployment via version control tools like Github.
These solutions make creating and deploying JAMstack + serverless applications quick and easy, but they do come with a few tradeoffs:
They are not fully open source
Developers do not have direct access to the cloud infrastructure their application runs on, so the ability to customize how applications are deployed and managed is limited.
More stringent limitations are placed on resource use. E.g. Fewer monthly free Lambda invocations and execution time limits on Lambdas.
DIY Solutions
DIY solutions generally fall under the heading of Infrastructure as Code, or IAC. IAC tools like Serverless Framework and AWS SAM allow the developer to describe the needed infrastructure in code. Using these tools, developers can create a repeatable, programmatic method of provisioning and deploying JAMstack + Serverless applications. Since you’re creating the infrastructure on your own AWS account, you have access to the underlying infrastructure if you need to customize things later.
The primary downsides of using these DIY solutions are:
The steep learning curve
The complexity involved in getting started
Finding a Middle Ground
After exploring a range of options for creating JAMstack + Serverless applications on both the DIY and JAMstack focused ends of the spectrum, we felt that there was room for a solution that fit somewhere in the middle.
5. Introducing Jolt
We built Jolt with the goal of providing the ease of use of Netlify or Vercel all on a user’s own infrastructure. Jolt is fully open source and the infrastructure that applications are run on is provisioned on the user’s AWS account to allow for more fine-grained control when it’s needed. We chose AWS as our cloud provider because of its prevalence in the industry and our comfort with the tools and services they provide.
5.1 The Core of Jolt
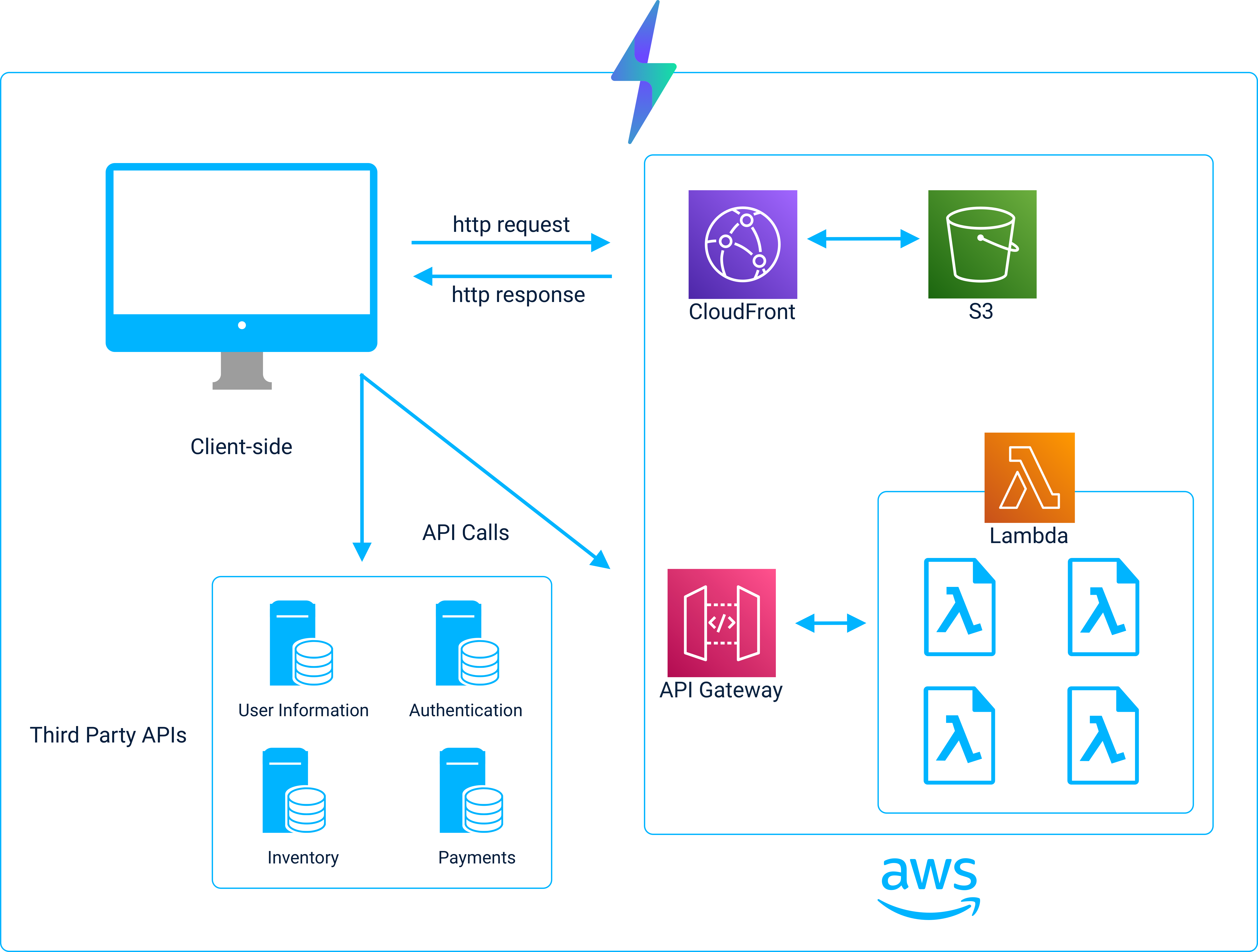
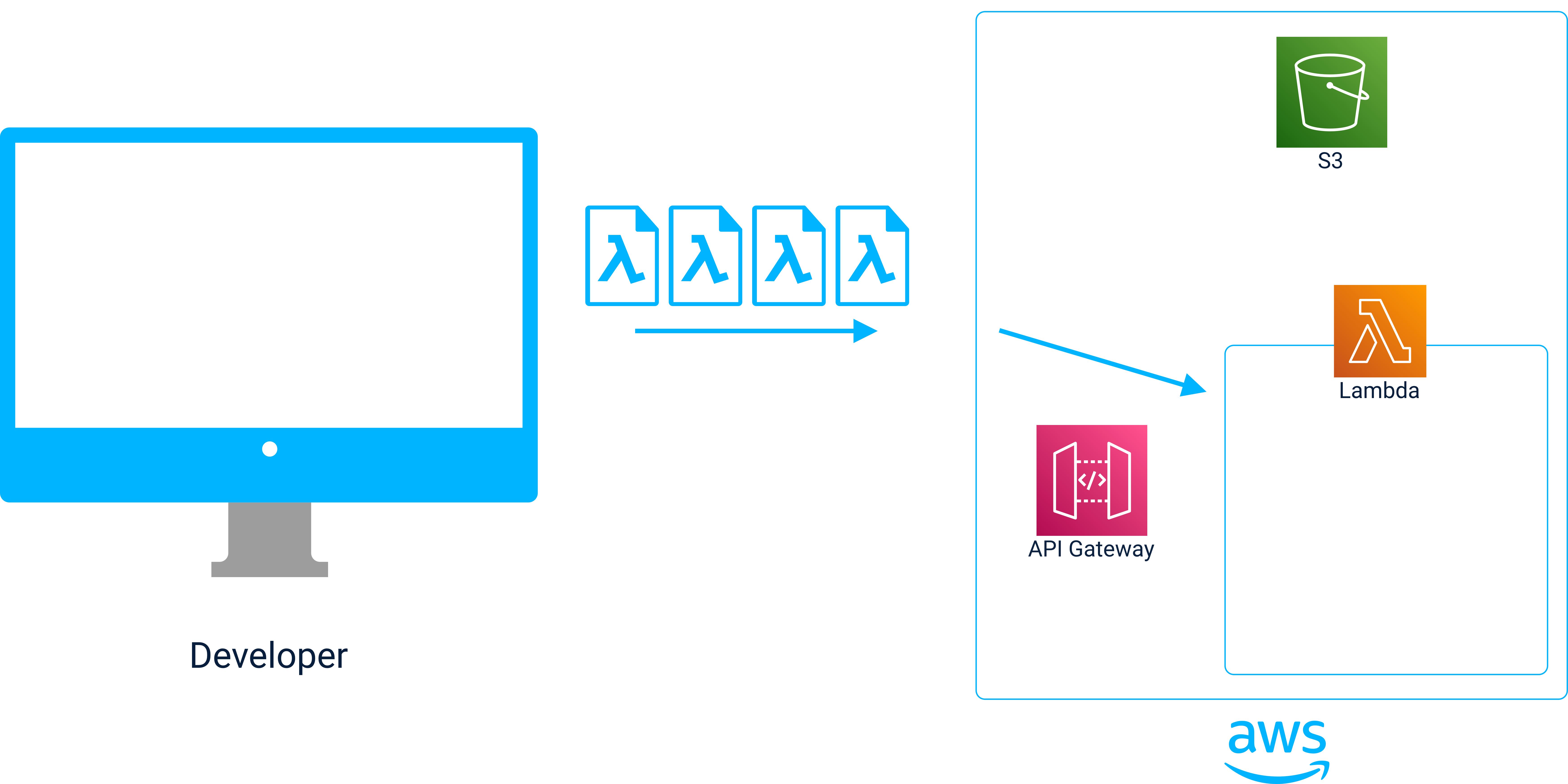
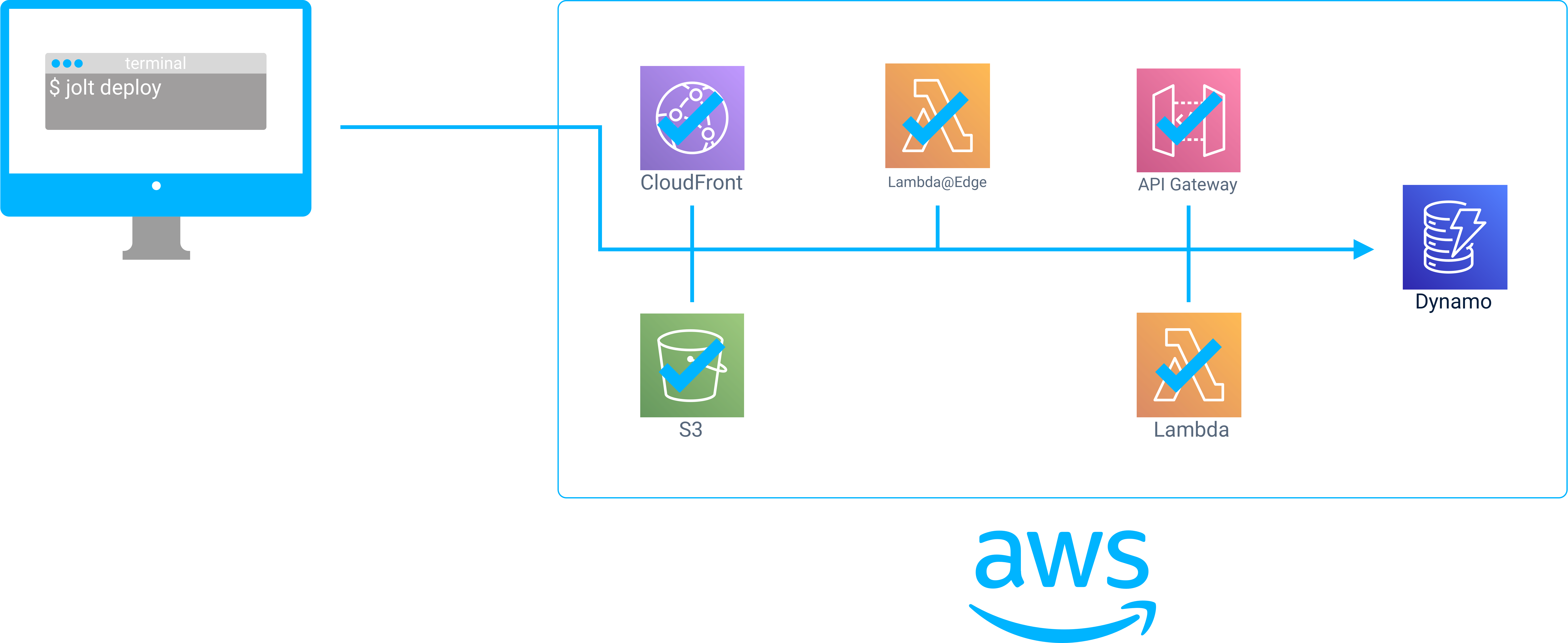
When we set out to build the core architecture, we decided to start by automating the 50+ steps involved in deploying a JAMstack + serverless application on AWS. Specifically, we wanted to provision: a CDN, a Static Asset Store (Origin), Serverless Functions and an API gateway all on AWS.
We decided to use AWS’ object store, S3, as the origin where static files are stored. Next, we use AWS’ CDN, CloudFront, to retrieve content from S3 and cache it on the global network of CDN servers.
For serverless functions, Jolt uses AWS Lambda. Finally, in order to invoke the Lambdas, an AWS API Gateway instance is created and each Lambda is integrated into the gateway as a separate route.
The core architecture of a Jolt application.
6. Developing and Deploying With Jolt
With the diagram of the core architecture of a Jolt application in mind, we’ll take a look at the 3 phases involved in deploying an application:
Setup
Building
Deployment
Setup
In order to provide an easy and intuitive developer experience, Jolt has some guidelines around how developers initialize and structure their applications.
Initialization
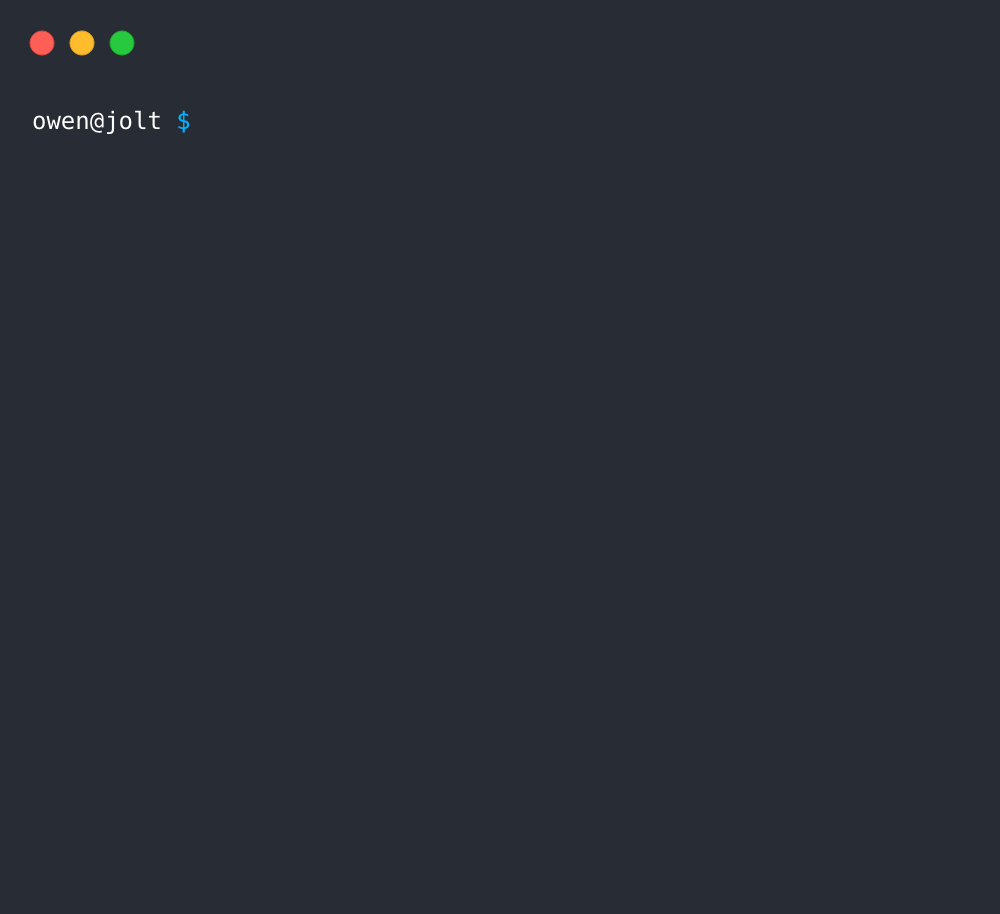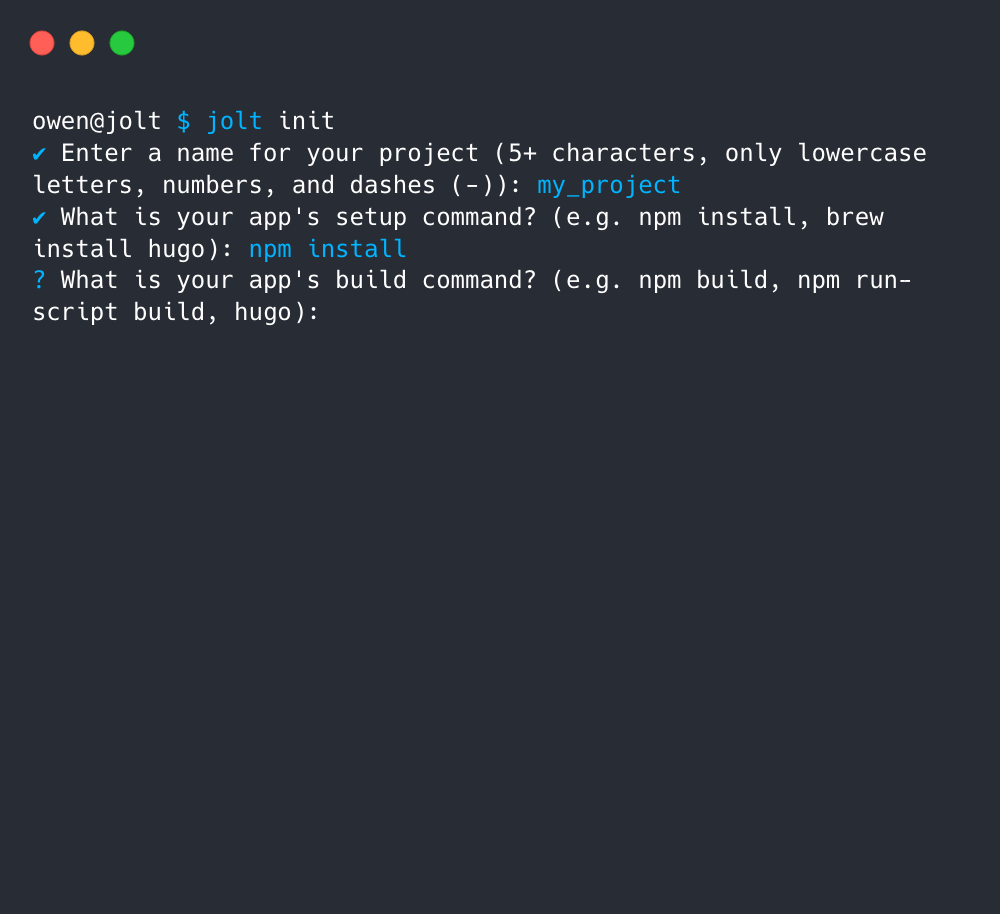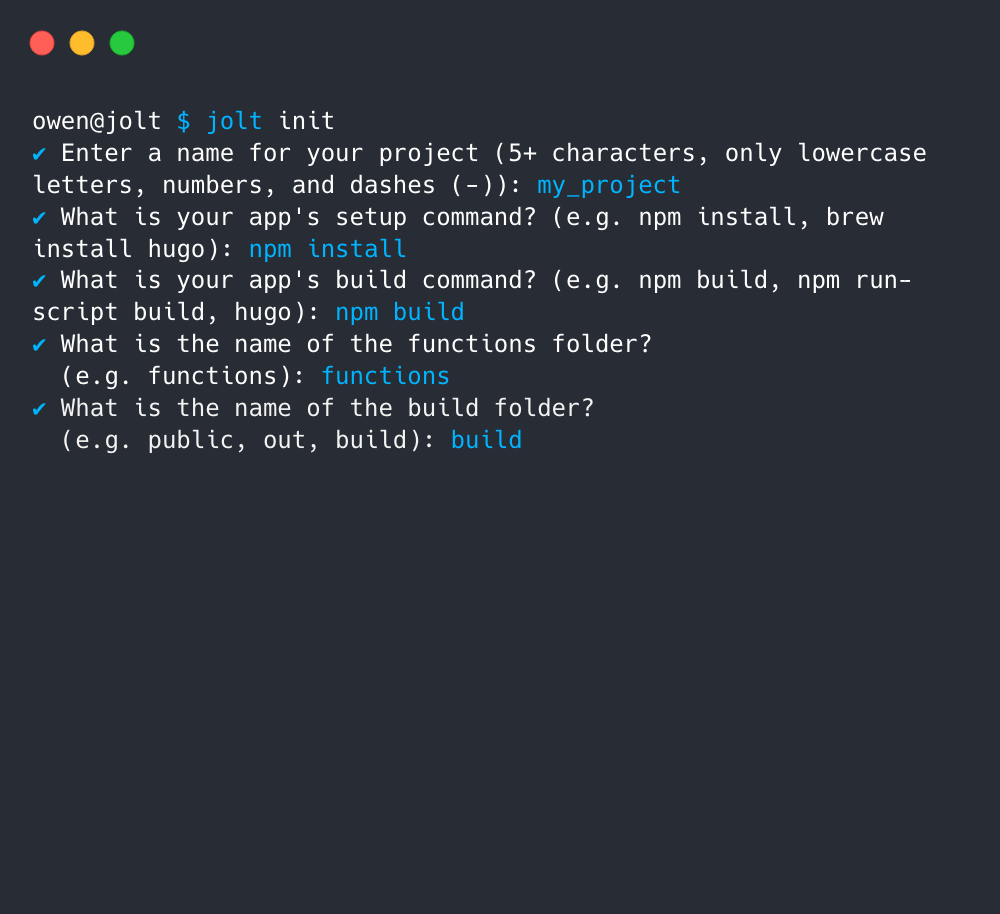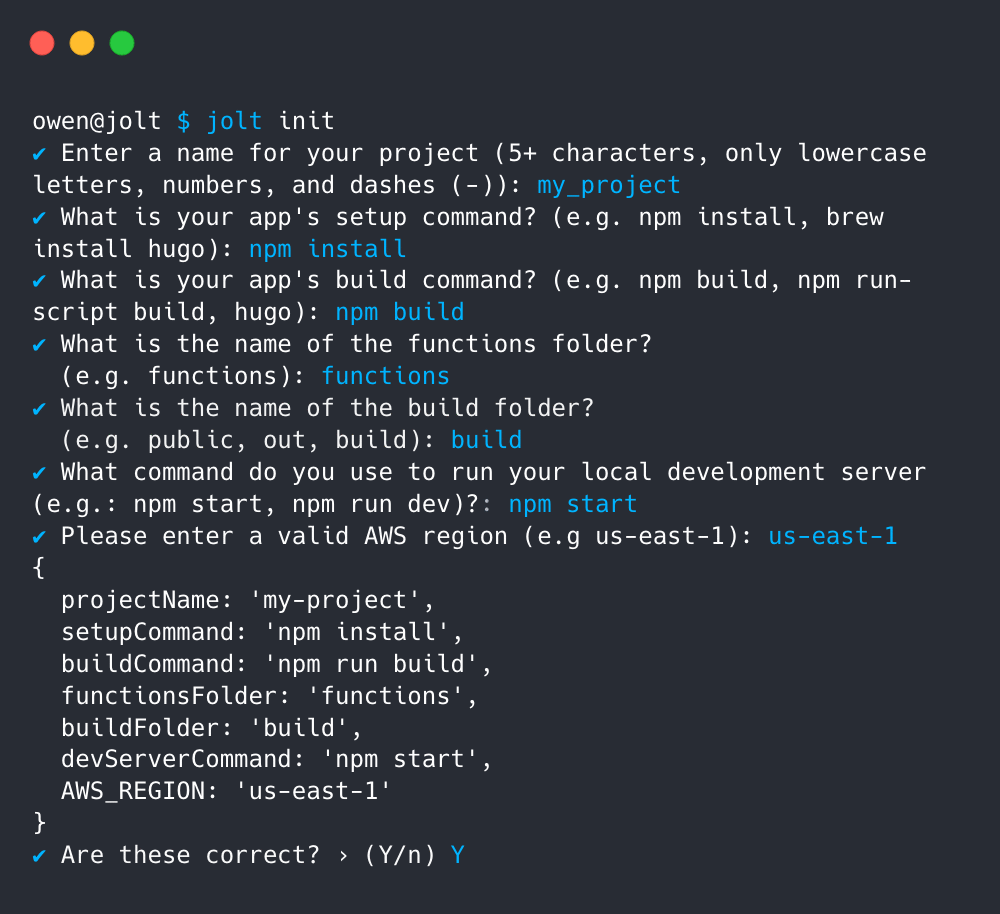
Before deploying an application, there are a few configuration details Jolt needs. Jolt uses the jolt init command to guide users through a series of prompts that gather this configuration information which is saved to a JSON file for later use. In particular, the information Jolt needs to deploy applications is as follows:
The dependency installation command (ie: npm install): Ensures that all of the dependencies required by the front-end and Lambdas are installed before deployment begins.
The build command (ie: npm run build): Builds the front end codebase into a collection of static assets prior to deployment.
The name of the user’s functions folder: The location where serverless functions and their environment variables are stored along with any dependencies.
The user’s default AWS region: Accessed during deployment to specify which region the infrastructure should be provisioned in.
The Functions Folder
Functions are defined in a separate functions folder located in the root of the application. The functions folder contains a collection of .js files, each of which represents a Lambda. In addition, a package.json file is needed in order to include any dependencies required by the functions. Finally, environment variables are defined in a .env file that lives alongside the functions.
Creating Functions
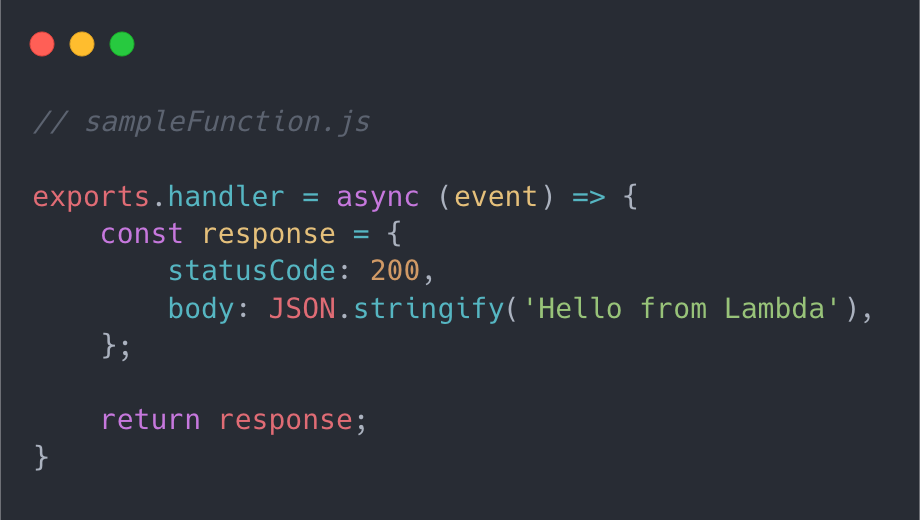
A basic Lambda function looks like this:
Each function must conform to the syntax required for all Lambdas, like the example above. (There are some additional parameters that are passed to the function when it is invoked which you can read more about here.)
Function Templates
For users who are unfamiliar with the Lambda syntax, or who want a shortcut for creating a Lambda, entering the command jolt lambda and the path they want the lambda to have will automatically create a function inside the user’s functions folder.
Creating a function template with jolt lambda.
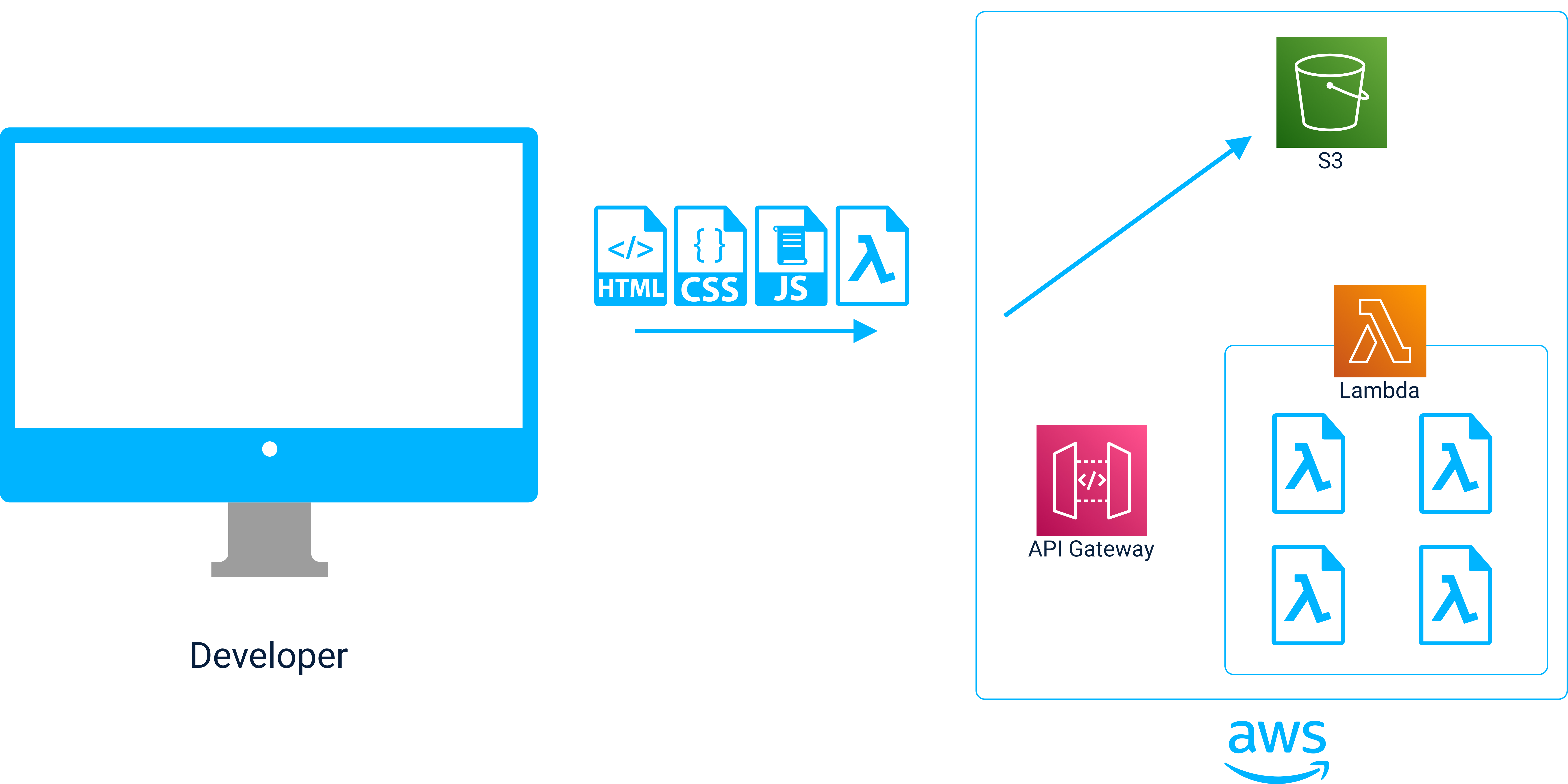
Building
Once the application is ready for deployment, the jolt deploy command makes sure that all required dependencies have been installed and then begins the build process using the build command specified by the user during initialization. The specifics of the build process vary depending on the build tool (gatsby build, react-scripts build, etc.) being used, but at a high level the following occurs:
Application code is compiled into a collection of static files
Static files are minified to to reduce file sizes by removing unnecessary white space, truncating variable names, etc. This results in smaller file sizes.
Code is transpiled to use syntax that is supported by older browsers
Wherever possible, code JavaScript, HTML and CSS is bundled into one file to save the client from needing to go through multiple request response cycles for a single page.
In addition to the building of front end application code, Jolt also prepares functions for deployment to AWS Lambda. Each function is zipped up along with its dependencies so that the function code and its environment variables can be sent to AWS during the deployment process.
Deployment
Jolt deploys a JAMstack + Serverless App with a single command.
Jolt Deploy
After running jolt deploy from the root of the application, the necessary infrastructure will automatically be provisioned on AWS and the application code along with the serverless functions will be deployed to CloudFront and Lambdas, respectively.
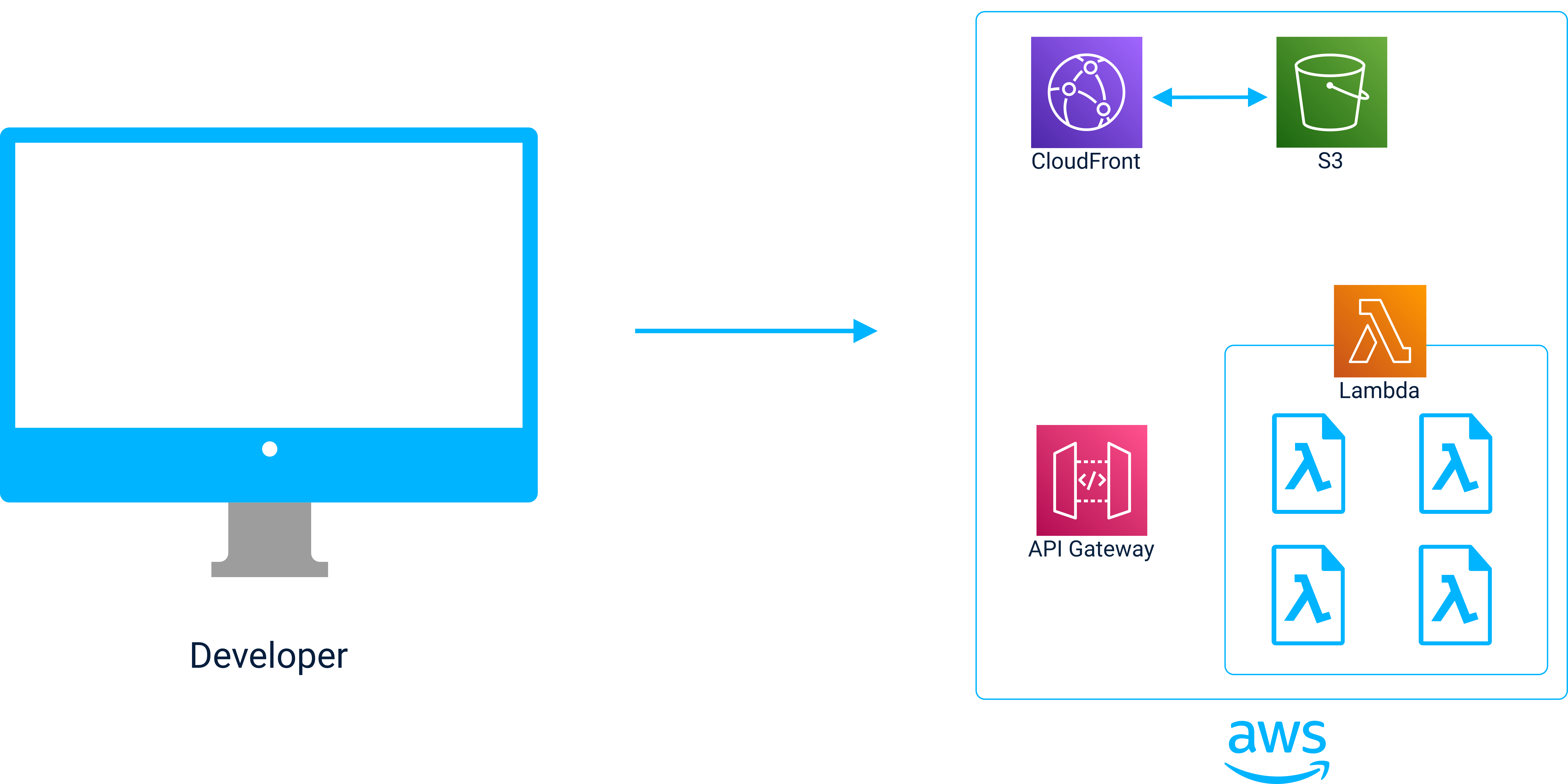
Creating a Bucket
The first step in the deployment process is to create a new bucket on S3. The S3 bucket serves as the origin for content cached on CloudFront.
Creating an API Gateway
Next, a new API Gateway is created. The gateway is used to proxy client requests to the appropriate Lambda.
Deploying Lambdas
Since AWS Lambda expects functions to be zipped before they are deployed. each function in the user’s functions folder gets zipped up along with any required dependencies and is sent off to S3 for storage.
For each function, its environment variables (if present) are retrieved from the local environment and a new Lambda is provisioned on AWS from the zipped function code (stored on S3) and the relevant environment variables.
Finally, a new route is created on the API Gateway that matches the path and name of the function within the functions folder and the newly created Lambda is integrated into the Gateway at that route.
Uploading Static Assets
After creating Lambdas and integrating them into the API Gateway, Jolt deploys the front end of the application. First, the static assets generated during the build process are sent to the S3 bucket.
Configuring CloudFront
Finally a new distribution is created on CloudFront. To do this, Jolt gives CloudFront the URL of the origin where the built application files are stored on S3. When requests for the application come into CloudFront, the requested content is retrieved from S3 and cached so that subsequent requests can be served without needing to go back to the origin.
Once the CloudFront distribution has been created, CloudFront begins propagating the new distribution to CDN servers all over the globe. This process can take upwards of 10 minutes to finish, but once complete, the new JAMstack + serverless application is live.
From the user’s perspective, the 50+ steps involved in manually provisioning and deploying the application are all automated and handled by the jolt deploy command.
7. Improving Jolt
Our initial vision for Jolt was to create a framework that made it easy to deploy JAMstack + serverless applications. With this accomplished, we discovered that there were a number of aspects related to development and management of applications that lacked the ease of use that we wanted to provide with Jolt. So, we decided to improve upon Jolt.
This process proved to have many technical challenges mainly due to two factors: we were working with cloud infrastructure and the JAMstack + serverless architecture was different from a more traditional three-tier architecture. Below are some of the key features we implemented while improving Jolt:
Relative paths for requests sent from the JAMstack application to serverless functions
Atomic deployment of infrastructure
Easy updates to existing Jolt applications
Rollbacks to revert the application to any previous version
Packaging of dependencies and environment variables for serverless functions
A local development environment for testing Lambdas
7.1 Implementing Relative Paths for Serverless Function Requests
The first feature that Jolt provides is the ability to use relative paths to connect the JAMstack application to serverless functions.
Before getting into how Jolt provides this functionality, a basic understanding of the difference between a relative and an absolute path is necessary.
An absolute path is analogous to a full mailing address. If they have the full path, a user can send a request to a location anywhere in the world. In the context of the web, an absolute path is usually a URL. A relative path is analogous to only knowing the apartment number of a location. You can only send a request there if you’re already in the building.
In a web application, if a request is made to a relative path, that request will be sent to the same origin (the same “apartment building”) at the relative path location (the “apartment number”).
For a web application that has its own back-end servers, relative path requests are sent to the back-end server by default. However, when sending requests to Lambdas, they need to be accessed via the API Gateway, which lives at a different origin and thus, can't be accessed with a relative path. Instead, Lambda requests need to be made using an absolute path.
This presents a problem for two reasons:
The same-origin policy prevents requests from being made between different origins (the client and the API Gateway) by default.
The developer doesn't know the address of the API Gateway while building the application because the gateway is only created after the application is deployed with Jolt.
CORS
To allow applications to send cross-origin requests, Jolt configures the API Gateway to allow cross origin resource sharing (CORS) when the gateway is provisioned.
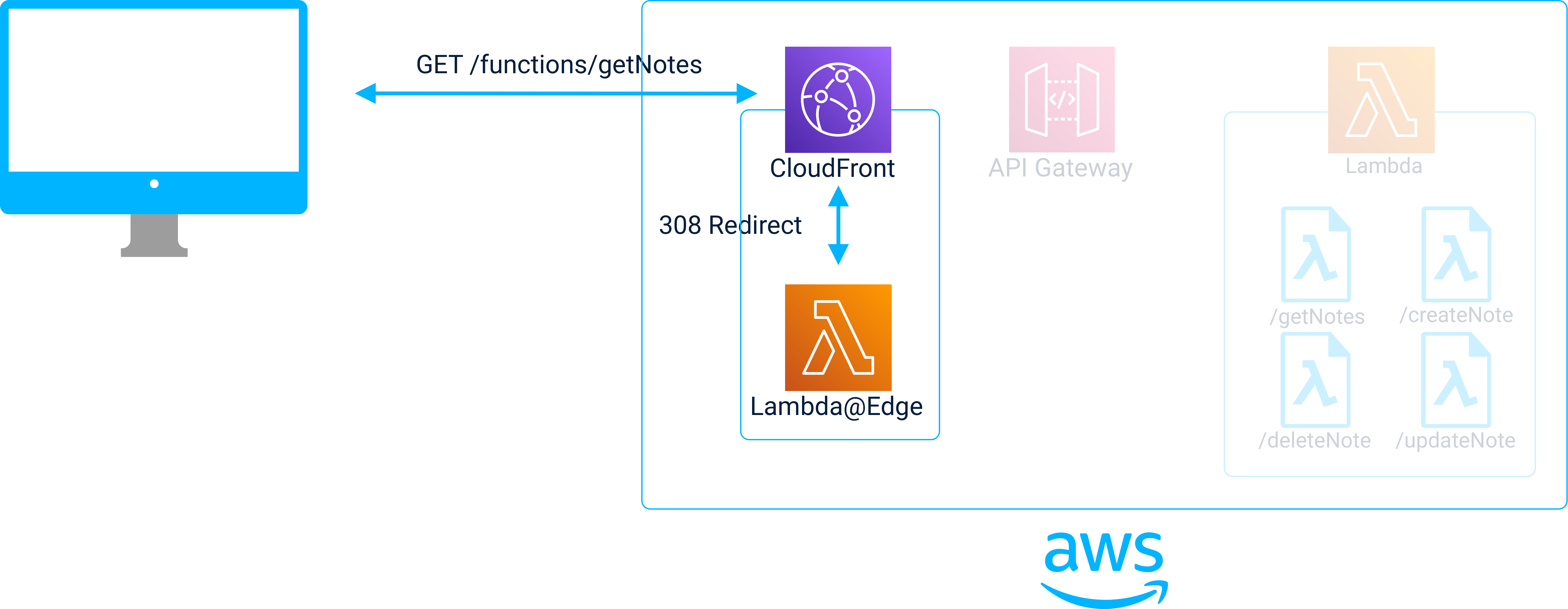
Lambda@Edge
To solve the problem of providing developers with a way to create requests to Lambdas before the API Gateway has been created, Jolt uses a feature of CloudFront called Lambda@Edge. Just like ordinary Lambdas, Lambda@Edge provides a scalable, serverless computing environment, however these Lambdas are invoked on CDN servers. This means that they live closer to clients than regular Lambdas and can also be used to intercept requests sent to CloudFront.
Jolt uses Lambda@Edge to do the following:
Receive client requests sent to CloudFront using a relative path.
Check to see if those requests are intended for a regular Lambda. By having developers add the path prefix /.functions to all Lambda requests made in their front-end code, Lambda@Edge can identify requests intended for Lambdas.
The Lambda@Edge responds to Lambda requests with a 308 Permanent Redirect. This response includes a location header that specifies the absolute path needed to reach the Lambda on API Gateway.
When the client receives the 308 response, it uses the URL in the location header to issue a new request using the same request method. This new request is sent to the intended Lambda via API Gateway.
An additional benefit of using a 308 Permanent Redirect is the fact that the API Gateway location will be cached in the browser. Future requests to the Lambda can then be sent directly to the API Gateway without requiring the initial request-response to Lambda@Edge.
A client request is received by Lambda@Edge which responds with a 308 Permanent Redirect
Next, the client follows the redirect to send the same request to the Lambda via API Gateway
7.2 Implementing Atomic Deployments of Infrastructure
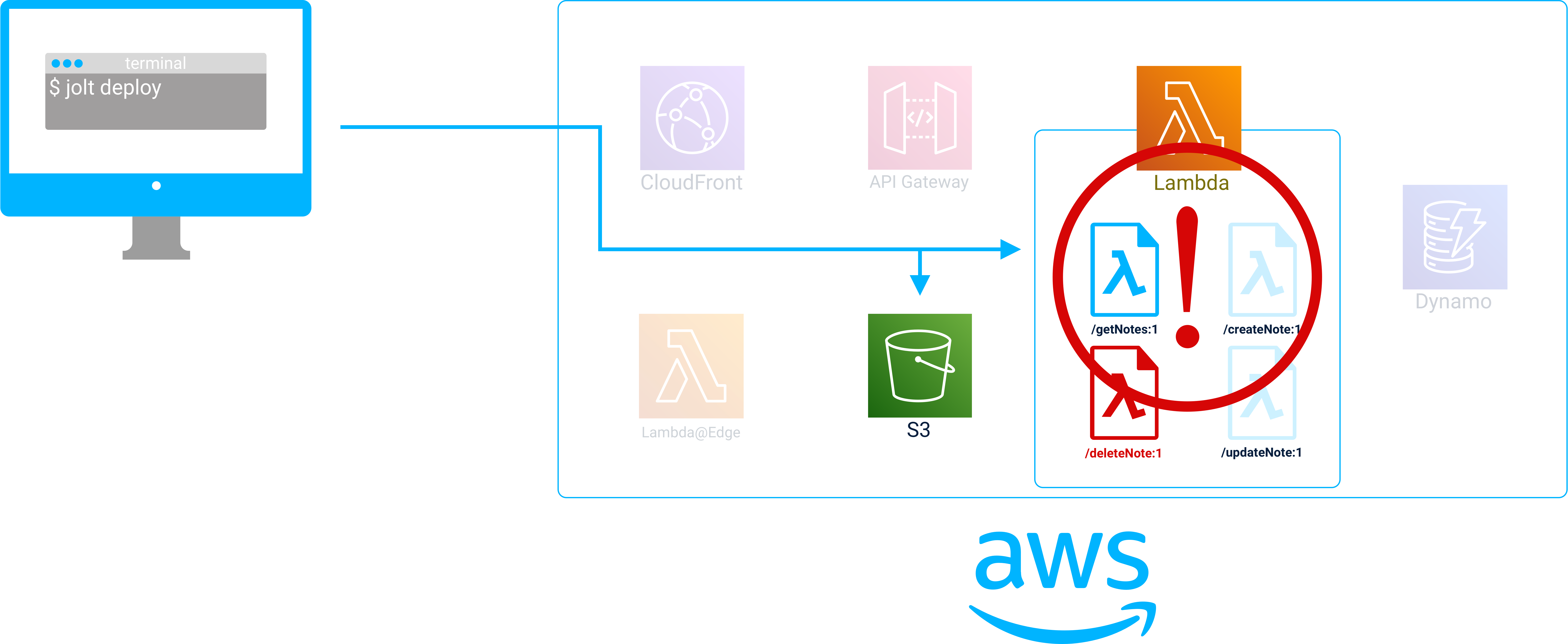
Another feature that Jolt provides is atomic deployments. In an atomic deployment, either all resources are deployed or none of the resources are deployed.
Errors can occur during deployment for many reasons including an incorrectly configured Lambda.
To understand why this is important, consider what happens when an error occurs in the middle of deployment. If Jolt crashed halfway through provisioning Lambdas for an application, the application would exist in a half finished state. While the application would most likely be non-functional, the already provisioned infrastructure would continue to exist on the user’s AWS account. To avoid this, Jolt needed a way to ensure that an application will be reverted to its original state if a deployment fails.
Jolt utilizes two different methods to achieve atomic deployments:
A runtime deployment data structure
Versioning of reusable infrastructure
Runtime Deployment Data Structure
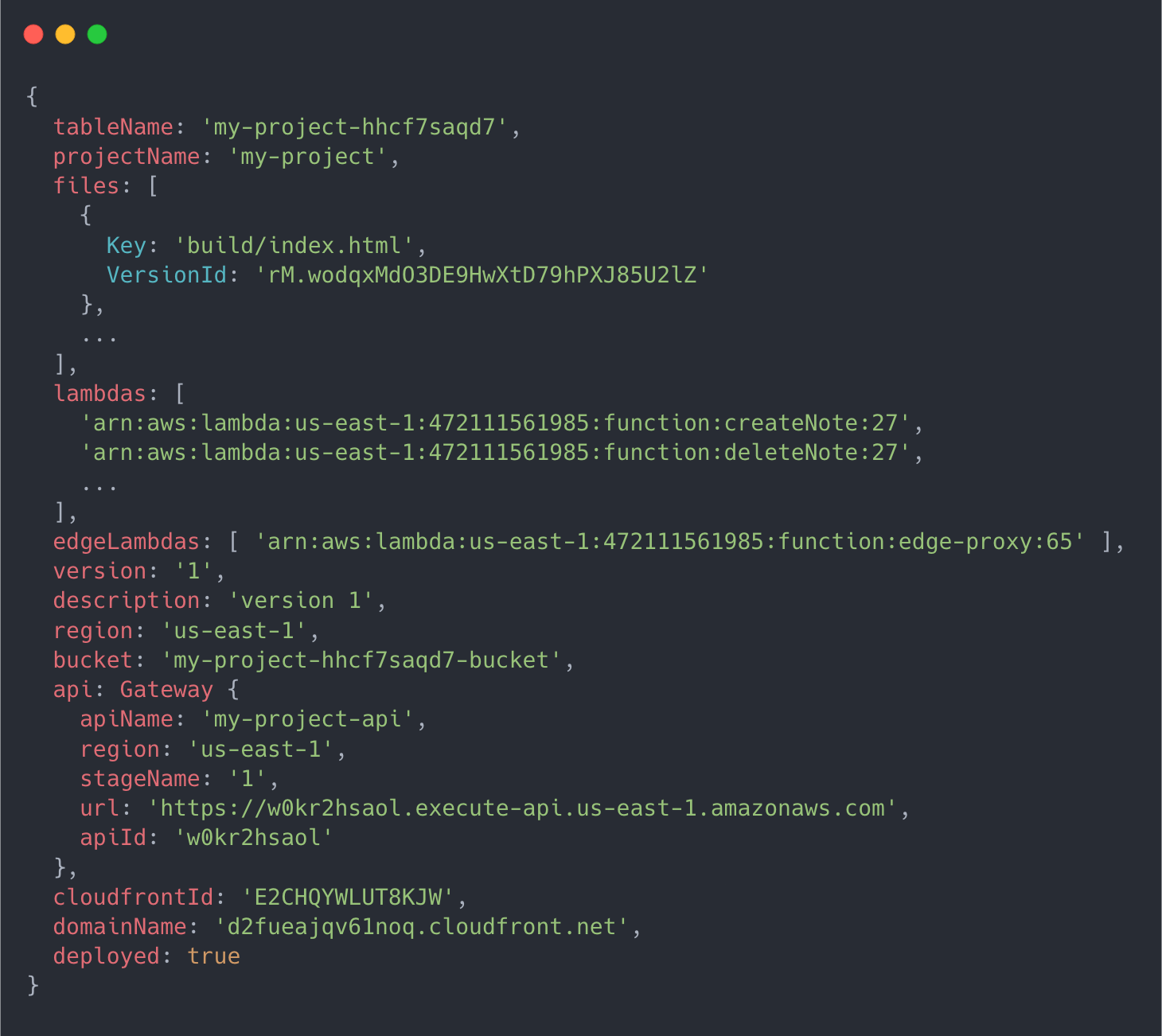
To keep track of the infrastructure that has been provisioned during runtime, Jolt tracks everything it has deployed so far in an Object data structure. As each piece of infrastructure is provisioned, an identifier for that piece (called an ARN) is added to the “deployment object” (the data structure). If an error occurs, Jolt initiates a teardown process that removes each piece of infrastructure contained in the deployment object. This way, the deployment fails without leaving any infrastructure artifacts behind on the user’s AWS account.
An example of a deployment object containing all of the infrastructure for a Jolt application.
However, using a deployment object at runtime does not handle situations where pre-existing infrastructure is being updated. If we naively delete every piece of infrastructure when deployment fails, the entire application will be removed. If the application is being updated to a new version, we’d like the old versions of each piece of infrastructure to be preserved if the update fails. In order to ensure that the old version remains if an update fails, we chose to version each reusable piece of infrastructure.
Versioning of Reusable Infrastructure
Versioning means creating a new version of the current infrastructure instead of overwriting it during a deployment. For Jolt applications: Lambdas, S3 Objects, API Gateway and the Lambda@Edge function are all resources that can be reused in successive updates by creating a new version of each.
Versioning in a nutshell: Each time a function is created, a new version is automatically created while maintaining all previous versions.
In an initial deployment, Jolt creates each of these resources and sets that resource as the first version. When an update occurs, if a piece of infrastructure already exists, a Lambda for instance, a new version of the Lambda is created rather than an entirely new instance of the Lambda. Versioning Lambdas and other resources in this way is a bit like adding layers to a cake. Rather than baking an entirely new cake every time, we simply create a new layer and place it on top of the old layer. This means that in the event of a failure, we can remove the top layer leaving behind the layer, or version, that existed before the update began.
By tracking infrastructure in a deployment object at runtime and also versioning each piece of infrastructure, Jolt ensures that deployments are atomic and eliminates the risk of deleting pre-existing infrastructure if a deployment or update fails.
7.3 Implementing Updates to Existing Applications
As we alluded to above, a third feature Jolt provides is the ability to update applications.
In order to update existing infrastructure, a way of keeping a persistent record of the current infrastructure an application is using is needed. A database can provide persistent storage for information about the current state of an application.
Choosing a Database
When determining which AWS database service to use for keeping track of application state, Jolt explored two potential options: RDS, a relational database service and DynamoDB, a document database service. In short, these were the tradeoffs:
Jolt uses DynamoDB because it fits the data persistence use case far better than RDS. Since each interaction Jolt has with the database uses an entire deployment object, normalizing the data into a relational style wouldn’t provide any benefits for Jolt’s use case. Additionally, by storing the deployment object as-is in the database, we avoid the need for designing and querying a complex relational schema.
With DynamoDB, when a user deploys an application, the deployment object is stored as a stringified JSON object and retrieval of the data for specific deployment is easily accomplished by querying for the desired object and deserializing it at runtime.
Using DynamoDB to Update
Once each piece of infrastructure has successfully been updated, a new deployment object is written to DynamoDB.
In order to update, Jolt queries the DynamoDB table for the previous deployment object, and uses this record of the existing infrastructure in order to reuse components wherever possible, and create new versions as needed. Once the update is complete, a new deployment object is written to DynamoDB that contains the infrastructure and versions associated with the updated application.
Updating CloudFront
Invalidate the Cache
By default, CloudFront caches content for a 24 hour period. This means that even after a new version of the application’s static assets has been sent to S3, CloudFront will continue to serve the stale cached content to clients until the 24 hours have ended.
To invalidate the cached content right away, Jolt sends a request to CloudFront that will clear out the currently cached version of the application. Now, as soon as the cache invalidation has propagated to a CDN server, the next request that server receives will fall through to the origin on S3 and the new version of the application will start being served to clients.
Update Lambda@Edge
Since Lambda@Edge is versioned just like regular Lambdas, Jolt creates a new version of it that redirects relative path requests with the ./functionsprefix so that they reach the new version of each Lambda on API Gateway. Once the new Lambda@Edge version has been deployed, Jolt updates the CloudFront distribution so that it uses the new Lambda@Edge version to intercept relative path requests.
7.4 Implementing Rollbacks
Another feature of Jolt is the ability to roll the application backwards or forwards to an earlier or later version.
Jolt performs a rollback in two phases:
Reverting the static assets to the specified version
Reverting the API to the specified version.
Reverting the Static Assets to the Specified Version
There are two ways of changing the current version of files on AWS S3 to an earlier version:
Delete all of the newest versions of each file until the desired version is the most recent.
This means that all of the deleted versions of files are lost, preventing users from rolling the application forward to a later version in the future.
Download the desired version of each file from S3 and then immediately reupload it so it becomes the latest version.
In this case, more space is used but all versions of the static files remain accessible.
We decided that the flexibility of being able to change an application to any version, both in the past or future, outweighed the cost of the extra storage associated with retaining all previous versions of each file. With Jolt, static assets are reuploaded to S3 when a rollback is performed so that they become the latest version.
In addition to reuploading files to S3, a rollback of static assets requires that the CloudFront cache be invalidated, just like during the update process. This way, the next time a request is made to CloudFront it will retrieve and cache the rollback version of each file from S3.
Reverting the API to the Specified Version
Reverting the API to a different version is challenging because:
Every Lambda that was accessible to version of the application’s static assets that are being rolled back to, needs to be available again and they should provide the same functionality that they did when the version was created.
Environment variables and dependencies for each Lambda need to be the same as they were when the version was created.
In order to allow the API Gateway to roll back to a particular version, Jolt needed a way of versioning the entire API so that each API version provides access to the appropriate versions of each Lambda needed by that version of the application.
To accomplish this, Jolt takes advantage of API Gateway stages. A gateway stage represents a snapshot of the API. In the context of a Jolt application, each stage can be thought of as a different version of the application’s API. Each time the application is deployed or updated, a new stage is created that provides access to the latest versions of each Lambda. Jolt uses the version number as the stage name. For example, version 4 of an application’s API might be accessed at the URL https://8z2d5ya0q4.execute-api.us-east-1.amazonaws.com/4
Finally, to change which stage an application is using, Lambda@Edge needs to be updated. Since Lambda@Edge is used to redirect clients to the API Gateway, Jolt updates Lambda@Edge so that the redirection sends clients to the gateway stage associated with the application version being rolled back to.
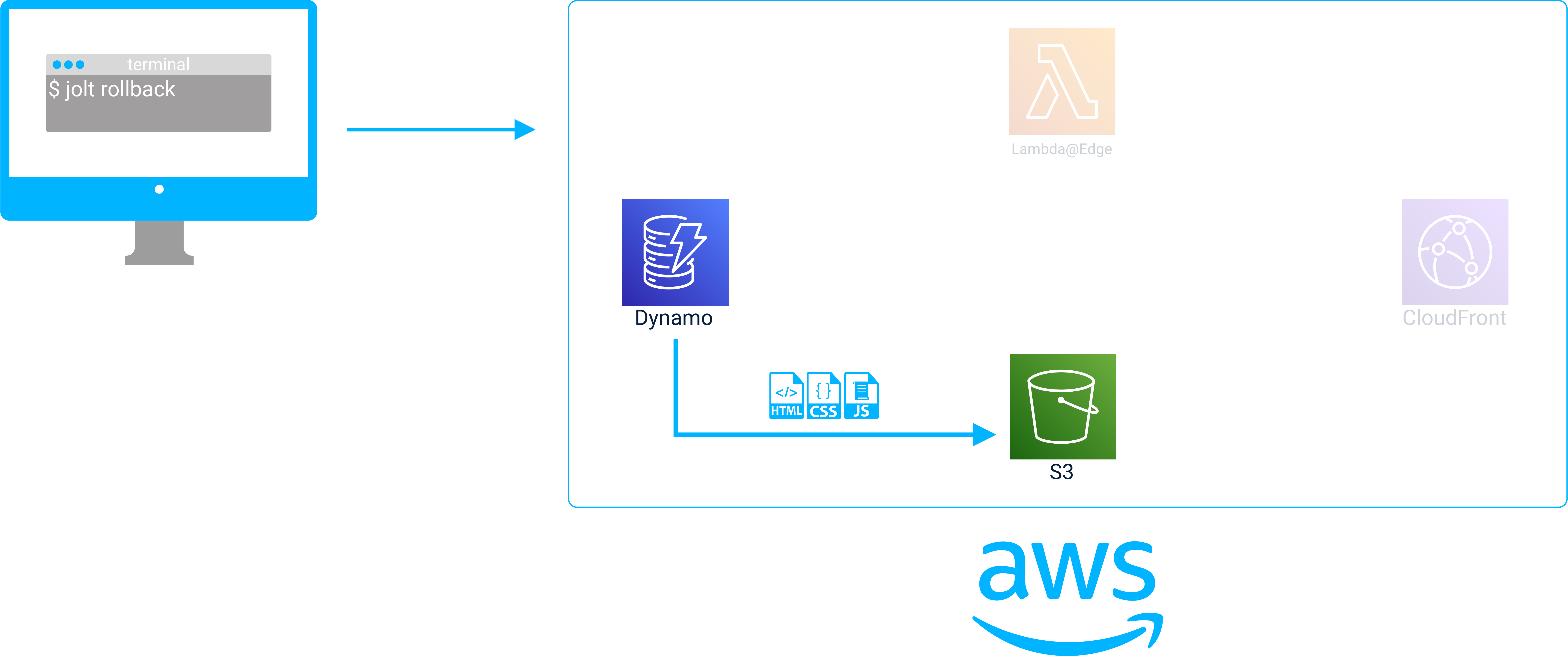
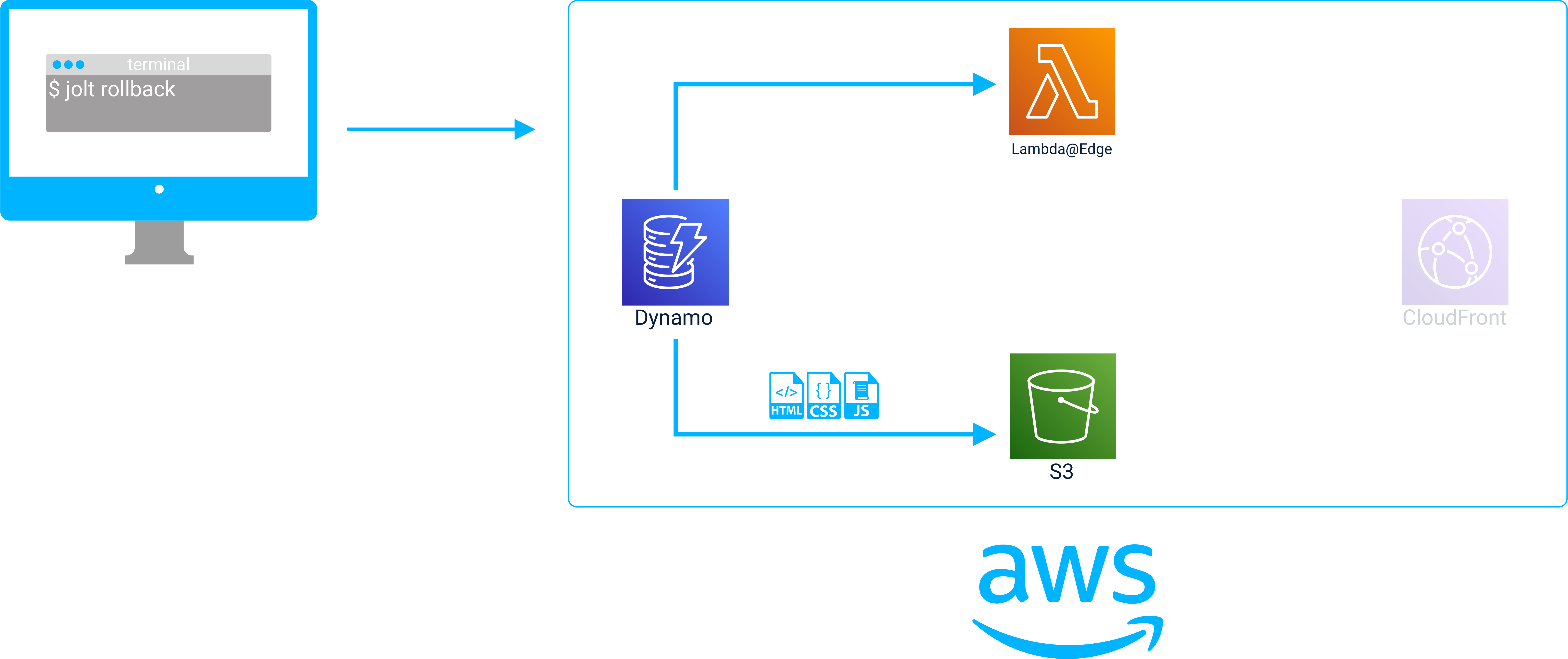
Before a rollback, client requests are redirected via the Lambda@Edge to stage/version 2 of the API Gateway.
The API Gateway proxies requests to a Lambda in stage/version 2 of the API.
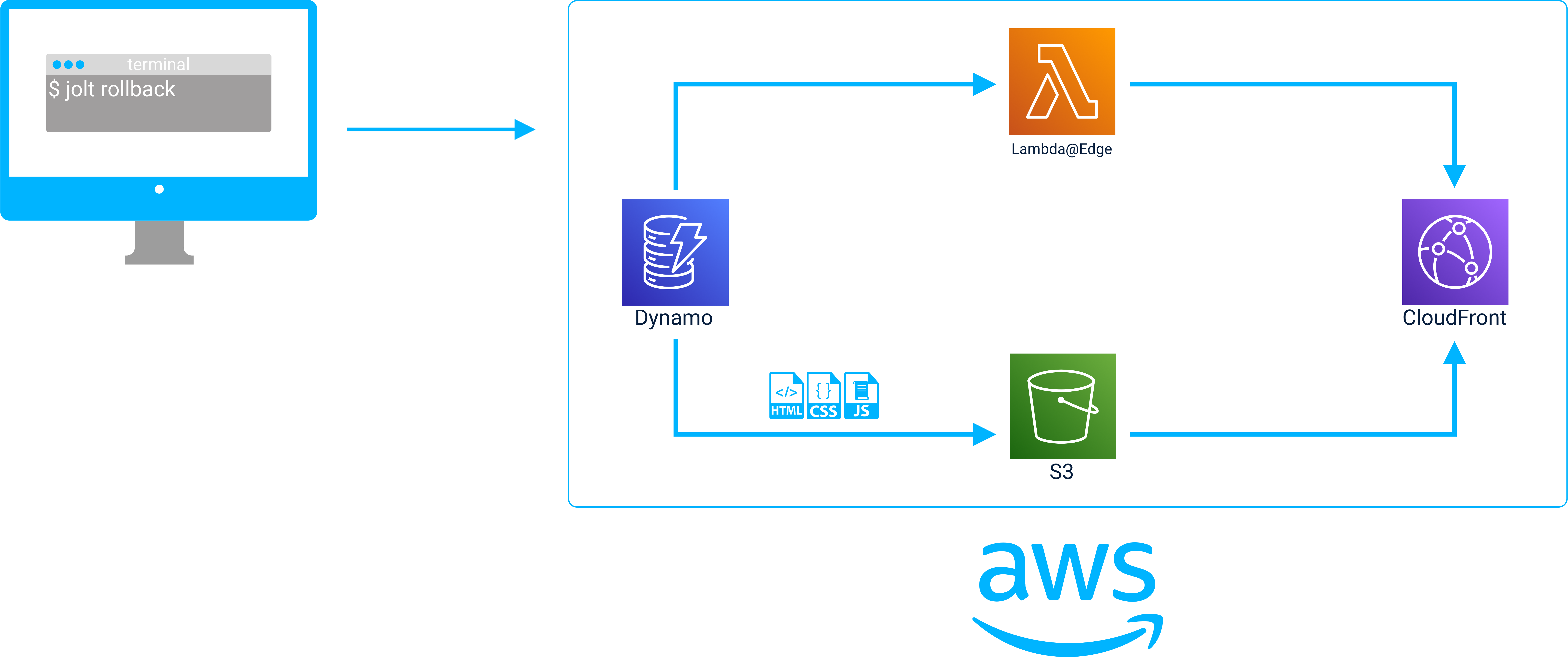
A rollback is performed with the jolt rollback command.
After the rollback is completed the Lambda@Edge redirects client requests to stage/version 1 of the API Gateway.
Now the API Gateway proxies requests to a Lambda in stage/version 1 of the API.
By updating Lambda@Edge to redirect clients to different API Gateway stages, Jolt can change the version of the entire API to the version expected by the static assets that were rolled back to. By tracking the gateway stage and static asset versions in the deployment object stored in DynamoDB, Jolt can keep both parts of the application in sync when it performs a rollback.
The Complete Rollback Process
When a rollback begins, the deployment object for the selected version is retrieved from DynamoDB and the static files recorded in the object are reuploaded to S3 so that they become the current version of the application.
Next, Lambda@Edge is updated to a version that will redirect clients to the API Gateway stage associated with the selected version of the application.
Finally, the CloudFront cache is invalidated so that the reuploaded files can be served to clients immediately. Then CloudFront is configured to use the new Lambda@Edge and the rollback is complete.
7.5 Packaging Function Dependencies and Environment Variables
Another feature Jolt provides is the automatic packaging of dependencies and environment variables for functions.
Packaging functions properly is key in providing a functional Jamstack + serverless application. If a developer needs a 3rd party library for use within a particular function or there is a secret key that the developer does not wish to share with outside parties, Jolt needs to ensure that they are included when the Lambda is provisioned on AWS.
Implementing this in code is technically difficult because Jolt versions Lambdas. With versioned Lambdas, Jolt can only specify dependencies and environment variables when the Lambda version is created. This is because a versioned Lambda cannot be changed after it has been deployed. For a single function, these limitations mean that Jolt has to:
Find all of its dependencies
Find its environment variables
Ensure that the environment variables are correctly mapped to their respective functions and are not available to other functions for security reasons.
Finding Function Dependencies: Zip It and Ship It
Building a method of packaging function dependencies from scratch would have involved parsing the code for each function recursively in order to find each dependency required by that function, each dependency required by those dependencies, and so on. In order to avoid this complexity, Jolt takes advantage of a pre-existing solution to gather function dependencies before deploying them.
Zip It And Ship It is a library created by Netlify that can parse a function and create a zip archive of that function and all of its dependencies. While Zip It And Ship It fits Jolt's needs almost perfectly, we made a few modifications to the library. Our modifications allow Lambdas to be created at a relative path that is derived from the relative path of the function within the Jolt functions folder. For example, if a developer has directories nested within their functions folder like functions/notes/all.js or functions/todos/all.js the original Zip It And Ship would provide the function name all to Jolt, which would result in two Lambdas being created at the same endpoint /all on the API Gateway (doing this would cause an error). Our version preserves the relative path of each function so that they can be reached at the endpoints /notes/all and /todos/all
Retrieving Lambda Environment Variables
By default, Zip It and Ship It ignores environment variables while packaging functions so Jolt utilizes a different solution to handle them.
Since packaging environment variables for Jolt functions needs to be done before a new function version is published, Jolt looks for a .env file in every subdirectory of the functions folder. A .env file contains a new-line separated list of environment variables. Before Jolt creates a Lambda, it checks to see if there is a .env file within the same directory as the function. If a .env file is found, the environment variables are retrieved and securely sent directly to AWS when the new Lambda version is created.
By customizing Zip It and Ship It to fit our needs, and implementing a way to add environment variables to specific Lambdas at runtime, Jolt automates the process of packaging functions with their required dependencies and environment variables when creating Lambdas.
7.6 Implementing a Local Development Environment for Testing
The final feature we added to Jolt is a local development environment that allows Lambda functions to be tested prior to deployment. When developing web applications that have a traditional back end, a variety of methods exist for running that back end locally during development. This is not the case with serverless functions.
With no way of running Lambdas locally during development, the only way of testing them or integrating them with the front end of an application is to deploy them to AWS during development. Then, if the Lambdas don’t function as intended, debugging must be performed remotely.
In order to make the process of testing and debugging Lambdas easier, we followed the lead of other JAMstack focused solutions like Netlify and Vercel and implemented a local Lambda server that allows developers to test and debug their Lambda code during development.
To ensure that it was reliable and intuitive to use, this local Lambda server provides the following:
Integration with a front end development server.
Support for both synchronous and asynchronous Lambda functions.
Real time logging of function output and error messages in the terminal to make it easier to diagnose and fix problems with functions.
Auto-loading of any environment variables into functions at runtime.
Updates to local function code take effect in real time without needing to restart the server.
Updates to local function code take effect in real time without needing to restart the server.
Mirroring the functionality of real Lambdas as closely as possible.
The core of this local Lambda server is an Express application. When requests are received by the server, the requested function is loaded, provided with the relevant environment variables and invoked with arguments designed to mimic the arguments given to Lambdas on AWS. By reloading functions with every request, the functions are not stuck as static function objects living in memory. This way, changes made to each function are represented on the server in real time.
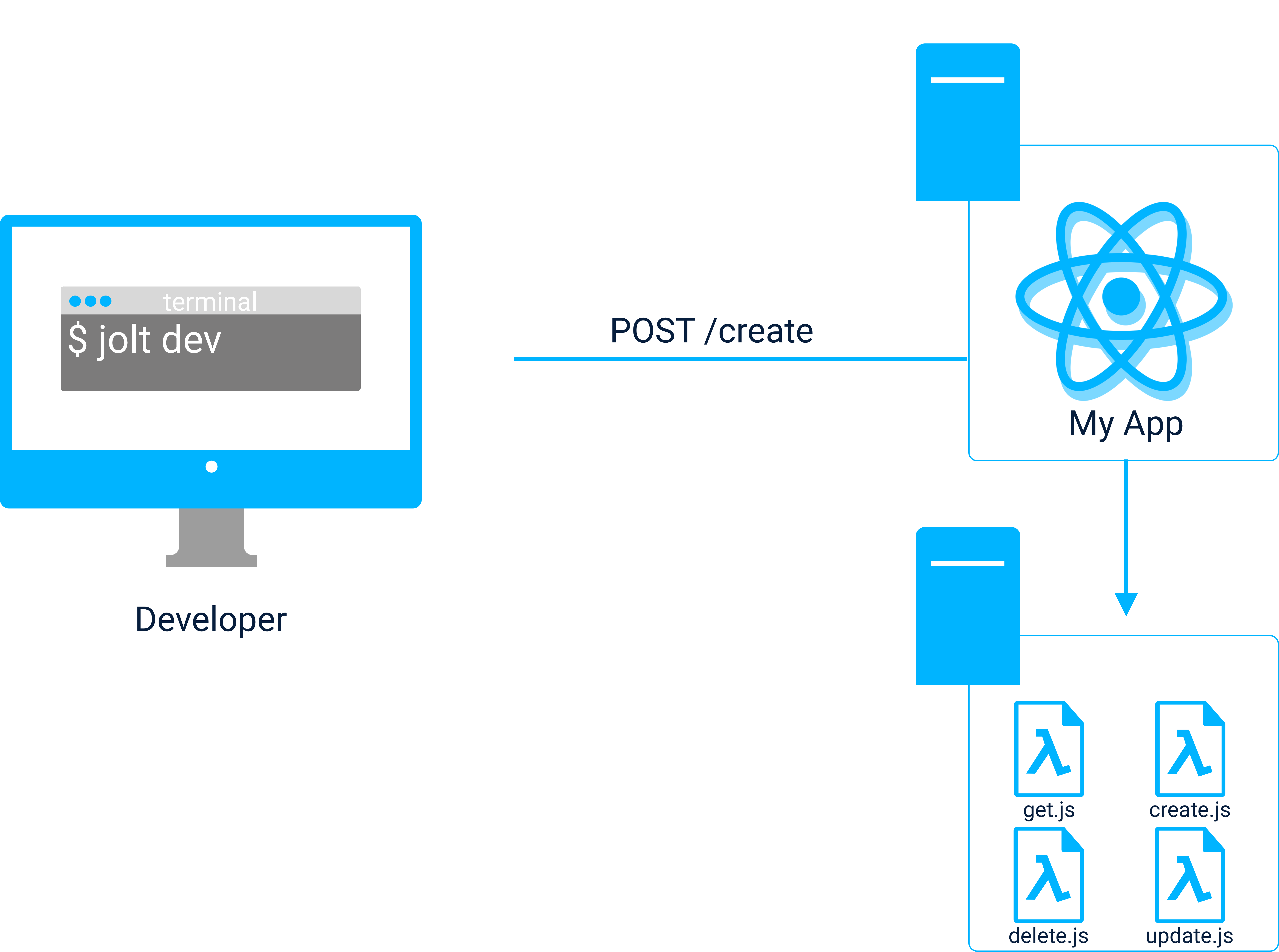
The lambda development environment can be spun up with two commands:
jolt dev runs the front end server and Lambda server simultaneously and requests from the front end are proxied to the requested function to allow the full JAMstack + serverless application to be run locally.
Using jolt dev during development to integrate the front end with serverless functions.
jolt functions runs the Lambda server by itself. This could be beneficial for a variety of use cases including unit testing or API testing with a tool like Postman.
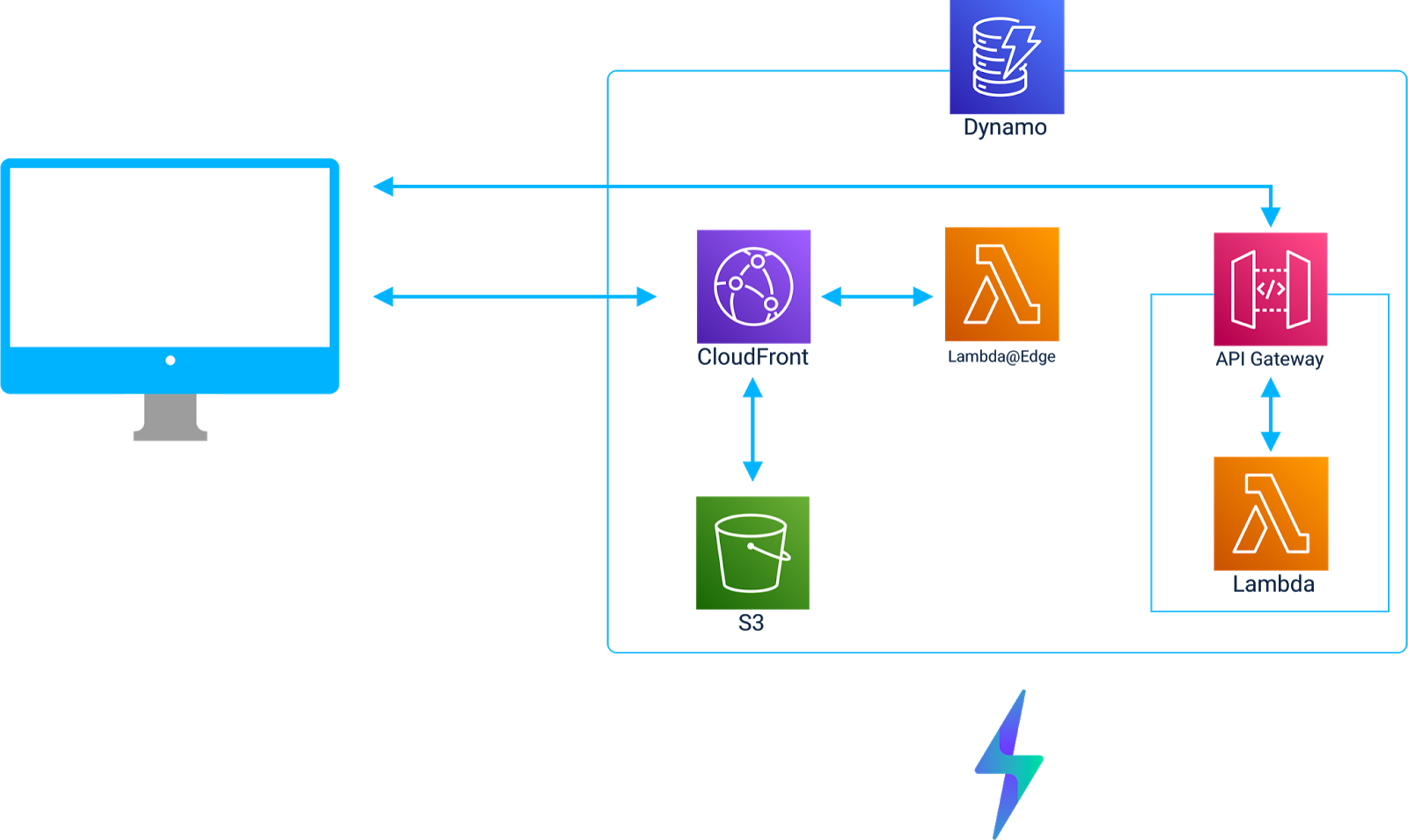
8. Final Architecture
With the additional features discussed above, the final architecture of Jolt looks like this:
From the perspective of a client:
Requests can be sent to CloudFront, and CloudFront returns cached static assets. If the cache is empty or has expired, CloudFront will retrieve the static assets from S3.
Requests for serverless functions are intercepted by Lambda@Edge.
Lambda@Edge responds with a 308 Permanent Redirect that tells the client to send the request to the API Gateway.
The client issues a new request to the API Gateway.
This triggers the appropriate Lambda to be invoked and a response is sent back to the client.
From the perspective of a developer:
All components of a JAMstack + serverless application are provisioned automatically.
Each deployment of the application is stored in a DynamoDB table.
The DynamoDB table is used for updates, rollbacks, and teardowns.
When a developer decides to make changes to an existing application, they can easily access any current or previously deployed version of the application.
Jolt can also be used to deploy and manage multiple applications and each application will have its own isolated infrastructure set.
9. Future Work
Some future work we have in mind includes:
Github integration using Github Actions that would allow for continuous deployment.
Adding dynamic routing for functions
Route53 integration to automate adding custom domain names